[论文解读] Foundational Models Defining a New Era in Vision: A Survey and Outlook
对 vision-language 基础模型的全面综述,详细介绍架构、训练目标、数据、微调、提示,以及挑战,并对未来方向给出展望。
Vision systems to see and reason about the compositional nature of visual scenes are fundamental to understanding our world. The complex relations between objects and their locations, ambiguities, and variations in the real-world environment can be better described in human language, naturally governed by grammatical rules and other modalities such as audio and depth. The models learned to bridge the gap between such modalities coupled with large-scale training data facilitate contextual reasoning, generalization, and prompt capabilities at test time. These models are referred to as foundational models. The output of such models can be modified through human-provided prompts without retraining, e.g., segmenting a particular object by providing a bounding box, having interactive dialogues by asking questions about an image or video scene or manipulating the robot's behavior through language instructions. In this survey, we provide a comprehensive review of such emerging foundational models, including typical architecture designs to combine different modalities (vision, text, audio, etc), training objectives (contrastive, generative), pre-training datasets, fine-tuning mechanisms, and the common prompting patterns; textual, visual, and heterogeneous. We discuss the open challenges and research directions for foundational models in computer vision, including difficulties in their evaluations and benchmarking, gaps in their real-world understanding, limitations of their contextual understanding, biases, vulnerability to adversarial attacks, and interpretability issues. We review recent developments in this field, covering a wide range of applications of foundation models systematically and comprehensively. A comprehensive list of foundational models studied in this work is available at \url{https://github.com/awaisrauf/Awesome-CV-Foundational-Models}.
研究动机与目标
- 在视觉领域定义基础模型及其对多模态理解的重要性。
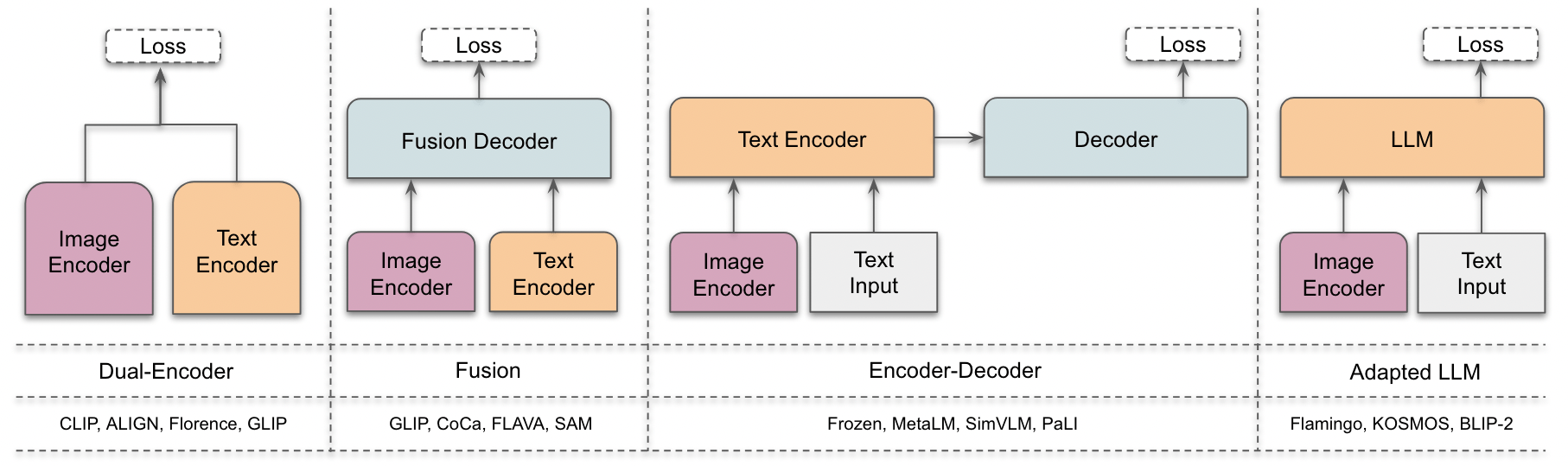
- 系统评述架构族群(双编码器、融合、编码器-解码器、改造的大模型)及训练目标(对比学习、生成、混合)。
- 分析预训练数据类型、微调策略和视觉-语言模型的提示工程。
- 讨论开放挑战如评估、偏见、鲁棒性和可解释性,并勾勒未来研究方向。
提出的方法
- 对跨文本提示、跨视觉提示、异质模态与具象化/具身类别的基础 vision 模型进行系统综述。
- 将架构分为双编码器、融合、编码器-解码器,以及改造的LLM 设计,并给出示例模型。
- 综合训练目标,包括对比、生成和混合损失及具有代表性的公式(例如 ITC、MLM、LM)。
- 概述大规模预训练数据源(图像-文本数据集、部分合成数据及其组合)以及提示/微调范式。
- 讨论评估挑战、偏见、对抗脆弱性和可解释性问题。
- 汇编一个社区资源中的基础模型最新列表(GitHub)。
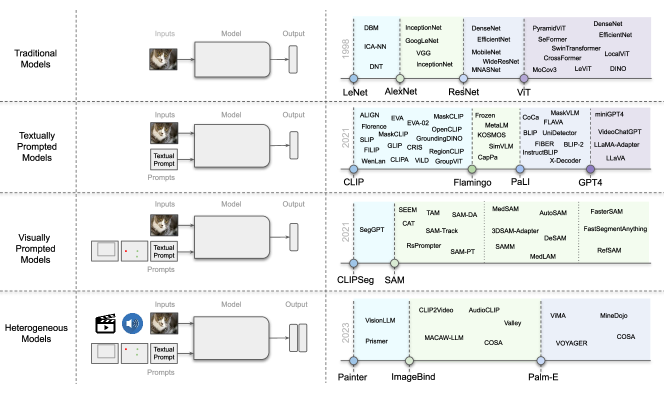
实验结果
研究问题
- RQ1视觉语言基础模型使用的架构模式是什么,它们在不同提示和模态下有何差异?
- RQ2训练目标和数据类型如何影响视觉语言模型的泛化和下游任务性能?
- RQ3将基础模型适配到下游视觉任务的常见微调与提示策略有哪些?
- RQ4在计算机视觉中,基础模型的关键评估挑战和开放研究方向是什么?
- RQ5当前的基础模型如何解决多模态环境中的偏见、鲁棒性和可解释性问题?
主要发现
- 基础模型通过提示在不重新训练的情况下实现对广泛视觉任务的零-shot 和少-shot 迁移。
- 文本提示模型分为对比、生成和混合方法,类似 CLIP 的架构是基础。
- 大规模图像-文本数据和多元化的预训练目标显著影响模型的泛化能力和下游性能。
- 提示工程和微调策略(指令遵循、定位/ grounding、任务特定适配)对于充分利用这些模型至关重要。
- 开放挑战包括评估困难、真实世界理解差距、偏见、对抗脆弱性和可解释性问题。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。