[论文解读] From Copilot to Pilot: Towards AI Supported Software Development
本论文评估 GitHub Copilot 在遵循 Pythonic 习语和 JavaScript 最佳实践方面的能力,并引入一个六级软件抽象分类法,以限定 AI 辅助代码完成的能力。
AI-supported programming has arrived, as shown by the introduction and successes of large language models for code, such as Copilot/Codex (Github/OpenAI) and AlphaCode (DeepMind). Above human average performance on programming challenges is now possible. However, software engineering is much more than solving programming contests. Moving beyond code completion to AI-supported software engineering will require an AI system that can, among other things, understand how to avoid code smells, to follow language idioms, and eventually (maybe!) propose rational software designs. In this study, we explore the current limitations of AI-supported code completion tools like Copilot and offer a simple taxonomy for understanding the classification of AI-supported code completion tools in this space. We first perform an exploratory study on Copilot's code suggestions for language idioms and code smells. Copilot does not follow language idioms and avoid code smells in most of our test scenarios. We then conduct additional investigation to determine the current boundaries of AI-supported code completion tools like Copilot by introducing a taxonomy of software abstraction hierarchies where 'basic programming functionality' such as code compilation and syntax checking is at the least abstract level, software architecture analysis and design are at the most abstract level. We conclude by providing a discussion on challenges for future development of AI-supported code completion tools to reach the design level of abstraction in our taxonomy.
研究动机与目标
- 评估以 Copilot 为代表工具的 AI 支持代码完成工具的当前边界。
- 评估 Copilot 在遵循 Pythonic 习语和避免 JavaScript 代码异味方面的能力。
- 提出一个软件抽象层次分类法,用于对 AI 支持的代码生成任务进行分类。
- 讨论向更高层次、面向设计的 AI 软件开发方向的挑战和未来方向。
提出的方法
- 从开源来源抽取 25 条流行的 Pythonic 习语和 25 条来自 AirBNB 指南的 JavaScript 最佳实践。
- 使用两部分输入触发 Copilot 提示(场景标题作为注释和最小代码)。
- 评估 Copilot 的前 10 个建议相对于所引述的习语和做法,以确定每个场景的通过/未通过。
- 将 Copilot 的表现与习语/做法进行比较,以评估与一般编码标准的一致性。
- 开发一个六级软件抽象分类法,以映射 AI 支持的代码完成的边界。
- 使用排序示例来说明跨越抽象等级的能力。
![Figure 3: Koopman’s Autonomous Vehicle Safety Hierarchy of Needs [ 26 ] . SOTIF = safety of the intended function.](https://ar5iv.labs.arxiv.org/html/2303.04142/assets/koopman_pyramid.png)
实验结果
研究问题
- RQ1RQ-1:AI 支持的代码完成工具当前的边界是什么?
- RQ2RQ-1.1:AI 支持的代码完成工具如何管理编程习语?
- RQ3RQ-1.2:AI 支持的代码完成工具如何通过最佳实践来管理无异味代码?
主要发现
- Copilot 在 25 条习语中有 2 条将 Pythonic 习语作为第一建议,在其余 23 条中的前 10 名中出现的有 8 条。
- 在前 10 条建议中,Copilot 对 15 条的习语没有给出惯用的 Pythonic 做法。
- 对于 JavaScript 最佳实践,Copilot 在 25 个案例中提供了符合指南的顶级建议,在剩下的 22 个案例中进入前 10 名的有 5 个。
- Copilot 在 25 个 JavaScript 场景中未能提供前 10 名的最佳实践。
- Copilot 在常见初级任务(例如数字求和、导入模块)上显示了更好的性能,但总体上仍难以持续产出符合习惯用语或最佳实践的代码。
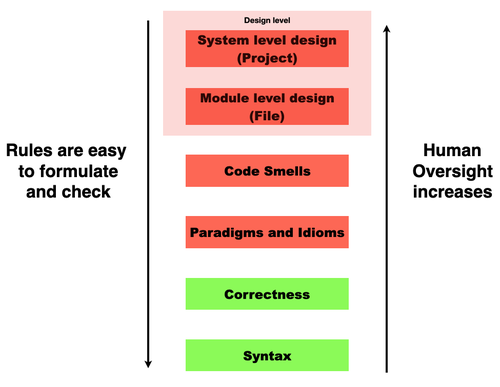
- 作者提出六级分类法(Syntax, Correctness, Paradigms/Idioms, Code Smells, Design),用于限定 AI 支持的代码生成能力,Copilot 在较低层次表现良好,在较高的架构/设计层面面临挑战。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。