[论文解读] FwdLLM: Efficient FedLLM using Forward Gradient
FwdLLM 引入 BP-free 训练与前向梯度和 PEFT,以实现在移动设备上对 LLM 的实用化联邦微调,实现大幅加速与显存下降。
Large Language Models (LLMs) are transforming the landscape of mobile intelligence. Federated Learning (FL), a method to preserve user data privacy, is often employed in fine-tuning LLMs to downstream mobile tasks, an approach known as FedLLM. Though recent efforts have addressed the network issue induced by the vast model size, they have not practically mitigated vital challenges concerning integration with mobile devices, such as significant memory consumption and sluggish model convergence. In response to these challenges, this work introduces FwdLLM, an innovative FL protocol designed to enhance the FedLLM efficiency. The key idea of FwdLLM to employ backpropagation (BP)-free training methods, requiring devices only to execute ``perturbed inferences''. Consequently, FwdLLM delivers way better memory efficiency and time efficiency (expedited by mobile NPUs and an expanded array of participant devices). FwdLLM centers around three key designs: (1) it combines BP-free training with parameter-efficient training methods, an essential way to scale the approach to the LLM era; (2) it systematically and adaptively allocates computational loads across devices, striking a careful balance between convergence speed and accuracy; (3) it discriminatively samples perturbed predictions that are more valuable to model convergence. Comprehensive experiments with five LLMs and three NLP tasks illustrate FwdLLM's significant advantages over conventional methods, including up to three orders of magnitude faster convergence and a 14.6x reduction in memory footprint. Uniquely, FwdLLM paves the way for federated learning of billion-parameter LLMs such as LLaMA on COTS mobile devices -- a feat previously unattained.
研究动机与目标
- 出于内存、加速器与可扩展性约束,激发 FedLLM 在移动设备上的实际可行性挑战。
- 提出通过扰动推理的 BP-free 训练,以降低设备端内存和计算量。
- 将 PEFT 方法与前向梯度训练结合,以扩展到大规模 LLM。
- 开发自适应扰动节奏与判别性扰动采样以加速收敛。
- 展示设备端的可行性并在多种模型和任务上量化性能提升。
提出的方法
- 将前向梯度作为对真实梯度的无偏估计,以实现 BP-free 训练。
- 将 BP-free 训练与参数高效微调(PEFT)方法(如 LoRa 与 Adapter)结合。
- 实现一个方差受控的节奏机制,只有当前向梯度方差低于阈值时才聚合梯度。
- 以判别性方式采样与真实梯度余弦相似度高的扰动,过滤掉低价值扰动。
- 使用一个自动离线 PEFT 性能分析器,根据梯度相似性为每个模型选择合适的 PEFT 方法。
- 利用云端-设备调度工作流,动态管理扰动与设备参与。
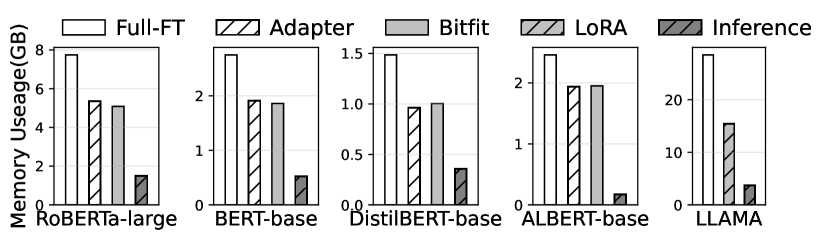
实验结果
研究问题
- RQ1BP-free 前向梯度训练结合 PEFT 是否能在移动设备上实现实用的 FedLLM?
- RQ2如何自动化扰动节奏与采样,以在收敛速度和计算成本之间取得平衡?
- RQ3相对于全模型微调与 PEFT 基线,能实现哪些内存、时间和精度的改进?
- RQ4在商用移动硬件上对亿参数 LLM(如 LLaMA)进行联邦基准测试是否可行?
主要发现
- 相比全模型微调,收敛速度最高提升至 217.3×。
- 内存占用相比强基线降低最高 14.6×。
- 在描述的设置下,设备端训练时间从 10.9–97.9 小时降至 0.2–0.8 小时。
- 在基线的基础上,BP-free + PEFT 的平均加速为 10.6×,范围为 2.0×–93.4×。
- 将 7B 的 LLaMA 模型在消费级智能手机上进行微调并量化到 INT4 时,在 10 分钟内完成。
- 判别性扰动采样和方差受控节奏被证明对收敛效率有显著影响。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。