[论文解读] GDformer: Going Beyond Subsequence Isolation for Multivariate Time Series Anomaly Detection
GDformer 引入一个全局字典增强的跨注意力 Transformer,配合原型学习整条序列的正常表示,用于无监督的多变量时间序列异常检测,在五个基准数据集上达到最先进的结果。
Unsupervised anomaly detection of multivariate time series is a challenging task, given the requirements of deriving a compact detection criterion without accessing the anomaly points. The existing methods are mainly based on reconstruction error or association divergence, which are both confined to isolated subsequences with limited horizons, hardly promising unified series-level criterion. In this paper, we propose the Global Dictionary-enhanced Transformer (GDformer) with a renovated dictionary-based cross attention mechanism to cultivate the global representations shared by all normal points in the entire series. Accordingly, the cross-attention maps reflect the correlation weights between the point and global representations, which naturally leads to the representation-wise similarity-based detection criterion. To foster more compact detection boundary, prototypes are introduced to capture the distribution of normal point-global correlation weights. GDformer consistently achieves state-of-the-art unsupervised anomaly detection performance on five real-world benchmark datasets. Further experiments validate the global dictionary has great transferability among various datasets. The code is available at https://github.com/yuppielqx/GDformer.
研究动机与目标
- 激励针对多变量时间序列的无监督异常检测,超越子序列孤立。
- 学习整条序列中由正常点共享的全局表示。
- 提供一种紧凑、基于相似性的异常检测准则,使用原型。
- 证明所学全局字典在不同数据集之间的迁移能力。
提出的方法
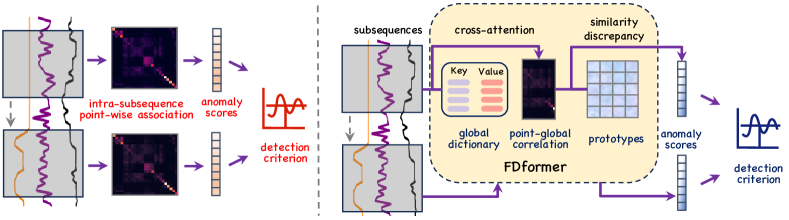
- 用基于字典的跨注意力机制替代标准自注意力,该机制在每层使用大小为 N 的全局 Key/Value 字典。
- 引入一个包含 P 个原型的相似性评估分支,以捕捉正常点–全球相关模式。
- 将重建损失与相似性-离散损失结合起来同时训练字典和原型(L_total = L_c - lambda L_s)。
- 根据与原型的跨注意力相似度计算异常分数,并对序列层级设定阈值进行检测。
- 输入子序列以固定概率掩蔽、归一化并在变换器层前进行嵌入。
实验结果
研究问题
- RQ1全局字典和跨注意力能否学习序列层面的正常表示,从而提升对比 Horizon 限制的子序列的异常检测?
- RQ2捕捉正常跨注意力权重分布的原型是否能实现紧凑、可靠的序列级检测准则?
- RQ3基于字典的方法是否能在不同数据集之间迁移,指示共享的正常时间模式?
主要发现
- GDformer 在五个真实世界基准上实现无监督异常检测的最先进性能。
- 全局字典使跨注意力具有低复杂度(O(TN)),相比标准自注意力的 O(T^2) 提升效率。
- 原型加上相似性-离散损失显著改善 F1 分数,相比仅重建或单一准则的基线。
- 消融研究显示跨注意力与多层相似性损失的组合达到最佳性能。
- 迁移实验表明全局字典和原型在不同数据集之间迁移良好,指示共享的正常模式。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。