[论文解读] Generalization bounds for neural ordinary differential equations and deep residual networks
本文推导基于 Lipschitz 的参数化 ODE 的泛化界,涵盖神经 ODE,并给出对深度残差网络的与深度无关的界,界项与连续权重差相关。
Neural ordinary differential equations (neural ODEs) are a popular family of continuous-depth deep learning models. In this work, we consider a large family of parameterized ODEs with continuous-in-time parameters, which include time-dependent neural ODEs. We derive a generalization bound for this class by a Lipschitz-based argument. By leveraging the analogy between neural ODEs and deep residual networks, our approach yields in particular a generalization bound for a class of deep residual networks. The bound involves the magnitude of the difference between successive weight matrices. We illustrate numerically how this quantity affects the generalization capability of neural networks.
研究动机与目标
- Motivate and study statistical properties of time-dependent neural ODEs and their relation to residual networks.
- Derive a generalization bound for parameterized ODEs that encompasses time-dependent and time-independent neural ODEs.
- Extend the bound to deep residual networks and compare with prior complexity results.
- Illustrate how the bound scales with model characteristics and provide numerical insight into weight-difference effects on generalization.
提出的方法
- Model neural ODEs as parameterized ODEs with time-varying parameters and Lipschitz-bounded components.
- Show well-posedness and Lipschitz continuity of the input-output map F_theta using Picard-Lindelöf and Grönwall’s inequality.
- Compute the epsilon-covering number of the parameter class Theta to control complexity.
- Derive a generalization bound with terms depending on the covering number and Lipschitz constants, yielding an O(n^{-1/4}) rate when parameters are infinite-dimensional.
- Specialize the bound to neural ODEs with time-independent W to recover an O(n^{-1/2}) rate.
- Extend the approach to deep residual networks by discretizing the ODE into a residual network and imposing a Lipschitz constraint on weight differences across layers.
- Provide a corollary for neural ODEs and a theorem for deep residual networks the bounds.
- Discuss how the depth-independence arises from the weight-difference constraint and analyze its implications.
实验结果
研究问题
- RQ1Can a Lipschitz-based complexity framework yield meaningful generalization bounds for neural ODEs and their discrete residual counterparts?
- RQ2How does the generalization error bound scale with the (i) number of basis functions m, (ii) parameter bounds R_theta, and (iii) Lipschitz constants K_f, K_theta?
- RQ3Does time-dependency (or time-independence) of neural ODEs affect the convergence rate of the generalization bound?
- RQ4What role do bounds on successive weight differences across layers play in achieving depth-independent generalization for residual networks?
主要发现
- A generalization bound for parameterized ODEs is established, applicable to time-dependent and time-independent neural ODEs, with a convergence rate that can be O(n^{-1/4}) due to infinite-dimensional parameters.
- For neural ODEs with time-invariant weights, a corollary delivers a standard O(n^{-1/2}) rate, matching classical finite-parameter results.
- A depth-independent generalization bound is derived for deep residual networks under a constraint on the maximum difference between successive weight matrices, with this bound remaining finite as depth grows.
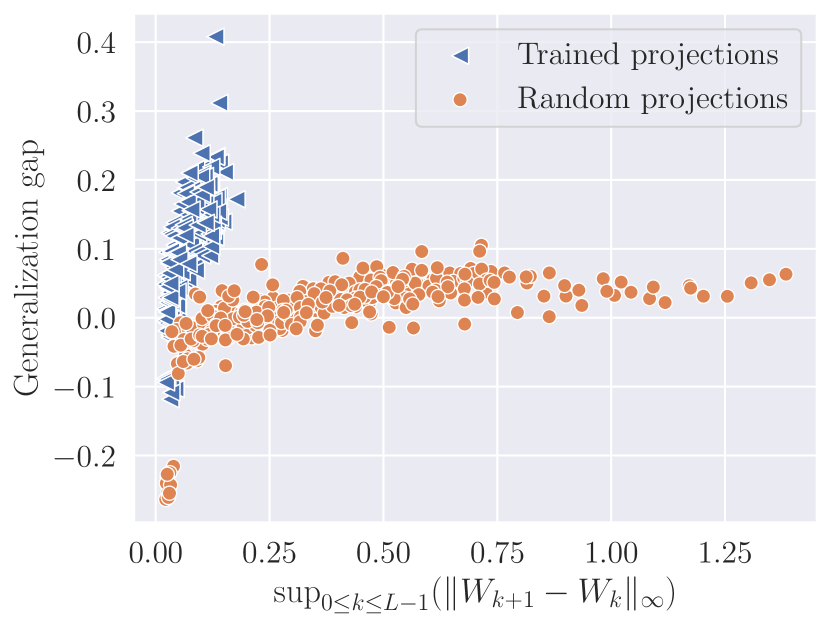
- The bound depends on a novel quantity: the magnitude of successive weight-matrix differences, providing empirical intuition via numerical illustrations linking weight changes to generalization gap.
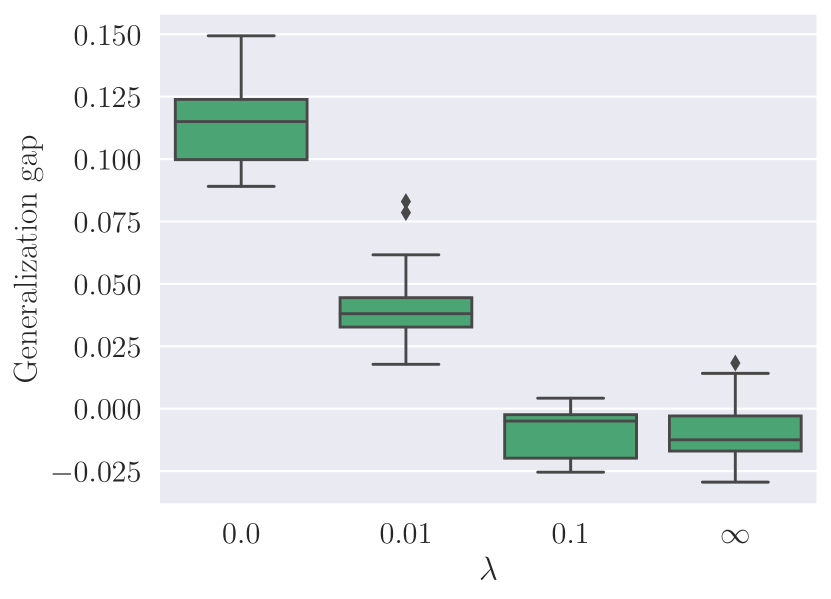
- Numerical experiments on MNIST demonstrate the relationship between the Lipschitz-like weight-difference measure and the generalization gap, and show the effect of a weight-difference penalty on generalization.
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。