[论文解读] Generative AI for Synthetic Data Generation: Methods, Challenges and the Future
本论文综述了庞大、固定的语言模型如何生成任务特定的合成数据,评审提示与适应方法,评估数据质量,并讨论应用与挑战及未来方向。
The recent surge in research focused on generating synthetic data from large language models (LLMs), especially for scenarios with limited data availability, marks a notable shift in Generative Artificial Intelligence (AI). Their ability to perform comparably to real-world data positions this approach as a compelling solution to low-resource challenges. This paper delves into advanced technologies that leverage these gigantic LLMs for the generation of task-specific training data. We outline methodologies, evaluation techniques, and practical applications, discuss the current limitations, and suggest potential pathways for future research.
研究动机与目标
- 激励在专业领域中通过生成合成数据来解决数据稀缺性和隐私问题。
- 考察如何在不重新训练模型的情况下,让庞大且固定的LLM生成任务特定的训练数据。
- 总结数据生成方法、质量评估和下游训练策略。
- 讨论实际应用并勾勒未来研究方向与待解决的挑战。
提出的方法
- 解释用于任务条件化数据生成的提示工程技术,包括属性受控提示和显化器(verbalizers)。
- 讨论用于数据生成的参数高效任务自适应方法(如适配器、前缀/提示微调、LoRA)。
- 描述数据质量测量方法(多样性、正确性、自然性)以及质量估计管线。
- 概述有效使用合成数据的训练策略,包括正则化和样本权重分配方案。
- 提供数据生成方法的分类法,并总结NLP领域的代表性系统与基准。
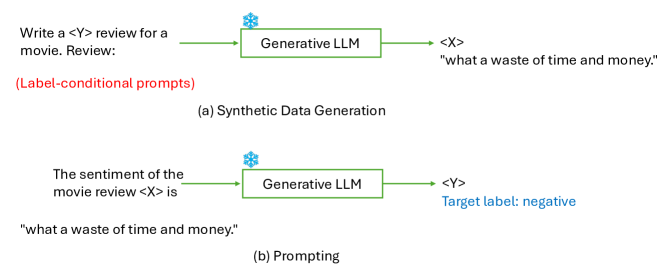
实验结果
研究问题
- RQ1在不重新培训它们的前提下,利用LLMs生成任务特定合成数据的主要方法有哪些?
- RQ2如何衡量并确保合成数据的质量以用于下游训练?
- RQ3在低资源或敏感领域,合成数据的实际应用及部署考虑有哪些?
- RQ4哪些挑战与未来方向影响生成型LLM合成数据的使用?
主要发现
- 已经出现了若干数据生成方法(如 ZeroGen、ProGen、MSP、FewGen),用于生成带标签或无标签的NLP任务合成数据。
- 合成数据的质量在多样性、正确性和自然性方面进行评估,正确性使用自动评估与人工评估。
- 提示工程和属性受控提示能够提高生成数据的相关性和多样性。
- 参数高效自适应使在不进行全模型微调的情况下实现任务特定数据生成成为可能。
- 合成数据在低资源和快速推理场景(包括医疗和教育领域)中展现出潜力,但也面临如幻觉生成和隐私等挑战。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。