[论文解读] Generative models improve fairness of medical classifiers under distribution shifts
本文表明在扩散式生成模型上对标签和敏感属性进行条件化,以扩增训练数据,能够在存在分布偏移时提升医学分类器在病理学、胸部影像学和皮肤科的鲁棒性与公平性。
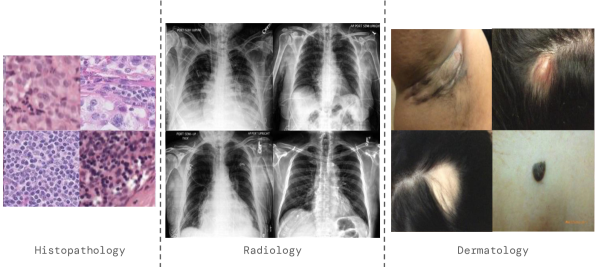
A ubiquitous challenge in machine learning is the problem of domain generalisation. This can exacerbate bias against groups or labels that are underrepresented in the datasets used for model development. Model bias can lead to unintended harms, especially in safety-critical applications like healthcare. Furthermore, the challenge is compounded by the difficulty of obtaining labelled data due to high cost or lack of readily available domain expertise. In our work, we show that learning realistic augmentations automatically from data is possible in a label-efficient manner using generative models. In particular, we leverage the higher abundance of unlabelled data to capture the underlying data distribution of different conditions and subgroups for an imaging modality. By conditioning generative models on appropriate labels, we can steer the distribution of synthetic examples according to specific requirements. We demonstrate that these learned augmentations can surpass heuristic ones by making models more robust and statistically fair in- and out-of-distribution. To evaluate the generality of our approach, we study 3 distinct medical imaging contexts of varying difficulty: (i) histopathology images from a publicly available generalisation benchmark, (ii) chest X-rays from publicly available clinical datasets, and (iii) dermatology images characterised by complex shifts and imaging conditions. Complementing real training samples with synthetic ones improves the robustness of models in all three medical tasks and increases fairness by improving the accuracy of diagnosis within underrepresented groups. This approach leads to stark improvements OOD across modalities: 7.7% prediction accuracy improvement in histopathology, 5.2% in chest radiology with 44.6% lower fairness gap and a striking 63.5% improvement in high-risk sensitivity for dermatology with a 7.5x reduction in fairness gap.
研究动机与目标
- 激发并解决医疗机器学习模型在分布偏移和潜在偏见方面的问题。
- 开发一种高效标签的扩增方法,利用扩散模型对子群体的数据分布进行建模。
- 证明学习到的扩增方法可以超越启发式扩增,在不牺牲准确性的前提下提高公平性。
- 展示该方法在多种成像模态、不同难度和分辨率下的泛化性。
提出的方法
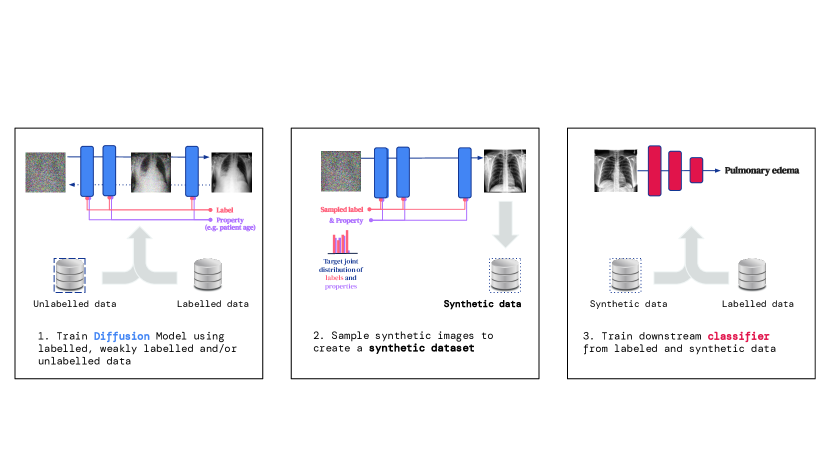
- 在带标签和未带标签的数据上训练扩散模型(以诊断标签为条件,或以诊断标签加敏感属性为条件)。
- 根据公平采样策略从扩散模型中采样合成图像。
- 在包含真实带标签数据和合成数据的混合数据上训练下游分类器,混合比例作为超参数。
实验结果
研究问题
- RQ1将扩散模型的增广条件化到标签和敏感属性上,是否能在分布偏移下提升性能?
- RQ2学习到的增广是否在病理学、胸部影像学和皮肤科的子群体之间降低公平性差距?
- RQ3与其他基线相比,该方法在高分辨率、高难度的皮肤科任务中的表现如何?
- RQ4将合成数据与颜色增强或其他启发式方法相结合对准确性和公平性的影响是什么?
主要发现
- 在病理学任务中,使用合成数据和颜色增强后,测试集准确率提升7.7个百分点。
- 在分布外的胸部放射影像任务中,平均AUC提升5.2个百分点,公平性差距降低44.6%。
- 在分布偏移下,皮肤科的高风险灵敏度提升63.5%,公平性差距降低7.5倍。
- 基于扩散的增广方法优于基线,在不同模态和分布偏移情景下减少公平性差距。
- 高分辨率皮肤科结果采用级联扩散上采样至256x256,在OOD情景下取得显著增益。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。