[论文解读] GPT as Knowledge Worker: A Zero-Shot Evaluation of (AI)CPA Capabilities
本文在两个 CPA 风格评估上基于 GPT-3.5(text-davinci-003)进行实验评估,覆盖金融、法律、会计与伦理任务的零样本表现。报告显示在算术挑战方面适中,但在 Assessment 2 上总体接近 57% 的准确率,以及在顶级两个答案正确方面表现出强劲的非蕴含性。
The global economy is increasingly dependent on knowledge workers to meet the needs of public and private organizations. While there is no single definition of knowledge work, organizations and industry groups still attempt to measure individuals' capability to engage in it. The most comprehensive assessment of capability readiness for professional knowledge workers is the Uniform CPA Examination developed by the American Institute of Certified Public Accountants (AICPA). In this paper, we experimentally evaluate OpenAI's `text-davinci-003` and prior versions of GPT on both a sample Regulation (REG) exam and an assessment of over 200 multiple-choice questions based on the AICPA Blueprints for legal, financial, accounting, technology, and ethical tasks. First, we find that `text-davinci-003` achieves a correct rate of 14.4% on a sample REG exam section, significantly underperforming human capabilities on quantitative reasoning in zero-shot prompts. Second, `text-davinci-003` appears to be approaching human-level performance on the Remembering & Understanding and Application skill levels in the Exam absent calculation. For best prompt and parameters, the model answers 57.6% of questions correctly, significantly better than the 25% guessing rate, and its top two answers are correct 82.1% of the time, indicating strong non-entailment. Finally, we find that recent generations of GPT-3 demonstrate material improvements on this assessment, rising from 30% for `text-davinci-001` to 57% for `text-davinci-003`. These findings strongly suggest that large language models have the potential to transform the quality and efficiency of future knowledge work.
研究动机与目标
- 评估 GPT-3.5 (text-davinci-003) 在基于 AICPA Uniform CPA Examination Blueprints 的知识工作任务中的零样本表现。
- 在四个 CPA 部分(AUD、BEC、FAR、REG)和两种评估设计上评估能力。
- 提供开源数据和提示以实现复现和进一步研究。
- 在可用的情况下,将 GPT-3.5 的表现与较早的 GPT-3 代际及人类基线进行比较。
提出的方法
- 两个评估,结构模仿 CPA 考试:Assessment 1(以 Regulat ion 为重点并含有算术推理)和 Assessment 2(涵盖所有四个 Blueprints 部分的 208 道综合多项选择题 MCQ)。
- 对 text-davinci-003 进行零样本提示,使用多种提示、情境化和论证策略;多个超参数(temperature 0.0/0.5/1.0;best_of 1/2/4)。
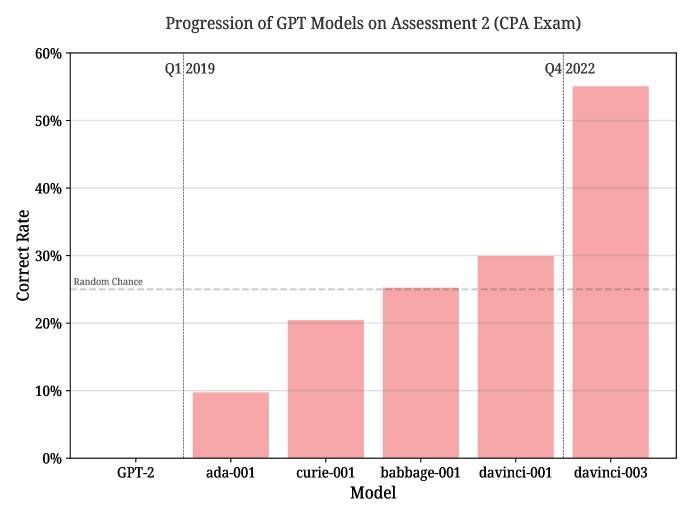
- 与较早的 GPT-3 模型(text-davinci-001、curie、babbage、ada)进行对比以展示进展。
- Assessment 2 的开源源代码和题目;复现细节在补充信息中提供。
实验结果
研究问题
- RQ1GPT-3.5 是否能够在零样本设置下跨学科的 CPA 领域担任知识工作者?
- RQ2在不同 CPA 部分(AUD、BEC、FAR、REG)以及评估设计(定量任务 vs. 定性任务)下,零样本 GPT-3.5 的表现有何差异?
- RQ3提示工程和模型超参数对专业知识任务的零样本表现有何影响?
- RQ4GPT-3.5 的顶两项正确率与单项正确率及猜测基线在各部分的比较如何?
主要发现
| Section | Accuracy | Accuracy - Top Two |
|---|---|---|
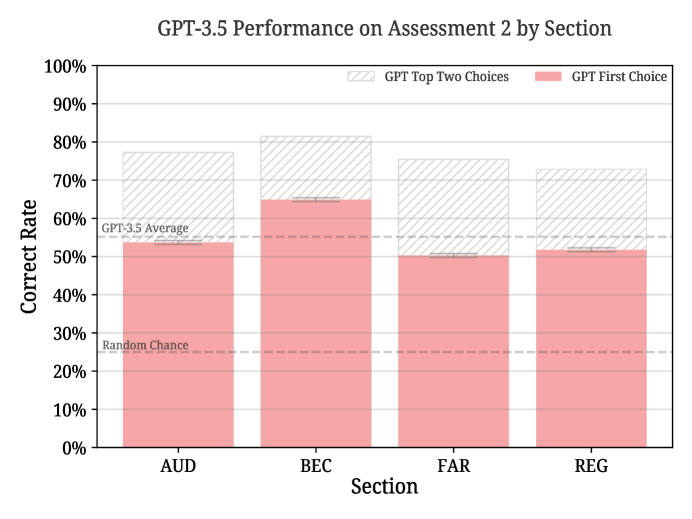
| AUD | 57.1% | 84.9% |
| BEC | 69.7% | 85.7% |
| FAR | 51.0% | 82.4% |
| REG | 53.1% | 75.8% |
- GPT-3.5 在 Assessment 1 的 Regulat ion-focused、算术密集任务上正确率为 14.4%,在定量推理方面表现逊于人类考生。
- 在 Assessment 2(跨所有部分的 208 道 MCQ)中,GPT-3.5 的正确率为 51.1%-57.6%,平均约 57%,顶两项正确约为 82%。
- 不同部分在最佳提示/参数下的表现:AUD 57.1%(顶两项 84.9%),BEC 69.7%(85.7%),FAR 51.0%(82.4%),REG 53.1%(75.8%)。
- GPT-3.5 展示出强烈的非蕴含性(顶两项正确)和改进的解释,尽管在大约 37% 的解释中会出现对参考文献的幻觉。
- 在 GPT-3 代际的演进中,text-davinci-003 在此知识工作任务集上显著超越 text-davinci-001 和更早的模型。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。