[论文解读] GPT-NER: Named Entity Recognition via Large Language Models
GPT-NER 将 NER 重新框架为对 LLM 的文本生成任务,使用带自我验证的实体标记输出以降低幻觉,并实现与有监督基线相竞争的结果,尤其在低资源环境中。
Despite the fact that large-scale Language Models (LLM) have achieved SOTA performances on a variety of NLP tasks, its performance on NER is still significantly below supervised baselines. This is due to the gap between the two tasks the NER and LLMs: the former is a sequence labeling task in nature while the latter is a text-generation model. In this paper, we propose GPT-NER to resolve this issue. GPT-NER bridges the gap by transforming the sequence labeling task to a generation task that can be easily adapted by LLMs e.g., the task of finding location entities in the input text "Columbus is a city" is transformed to generate the text sequence "@@Columbus## is a city", where special tokens @@## marks the entity to extract. To efficiently address the "hallucination" issue of LLMs, where LLMs have a strong inclination to over-confidently label NULL inputs as entities, we propose a self-verification strategy by prompting LLMs to ask itself whether the extracted entities belong to a labeled entity tag. We conduct experiments on five widely adopted NER datasets, and GPT-NER achieves comparable performances to fully supervised baselines, which is the first time as far as we are concerned. More importantly, we find that GPT-NER exhibits a greater ability in the low-resource and few-shot setups, when the amount of training data is extremely scarce, GPT-NER performs significantly better than supervised models. This demonstrates the capabilities of GPT-NER in real-world NER applications where the number of labeled examples is limited.
研究动机与目标
- 通过将 NER 重新框架为一个生成任务来弥合 NER 与 LLM 生成之间的差距。
- 设计提示和检索策略,为 LLM 提供结构良好的示例演示。
- 通过自我验证步骤在 NER 中缓解 LLM 的幻觉。
- 在平坦和嵌套的 NER 基准上评估 GPT-NER,并分析低资源下的性能。
提出的方法
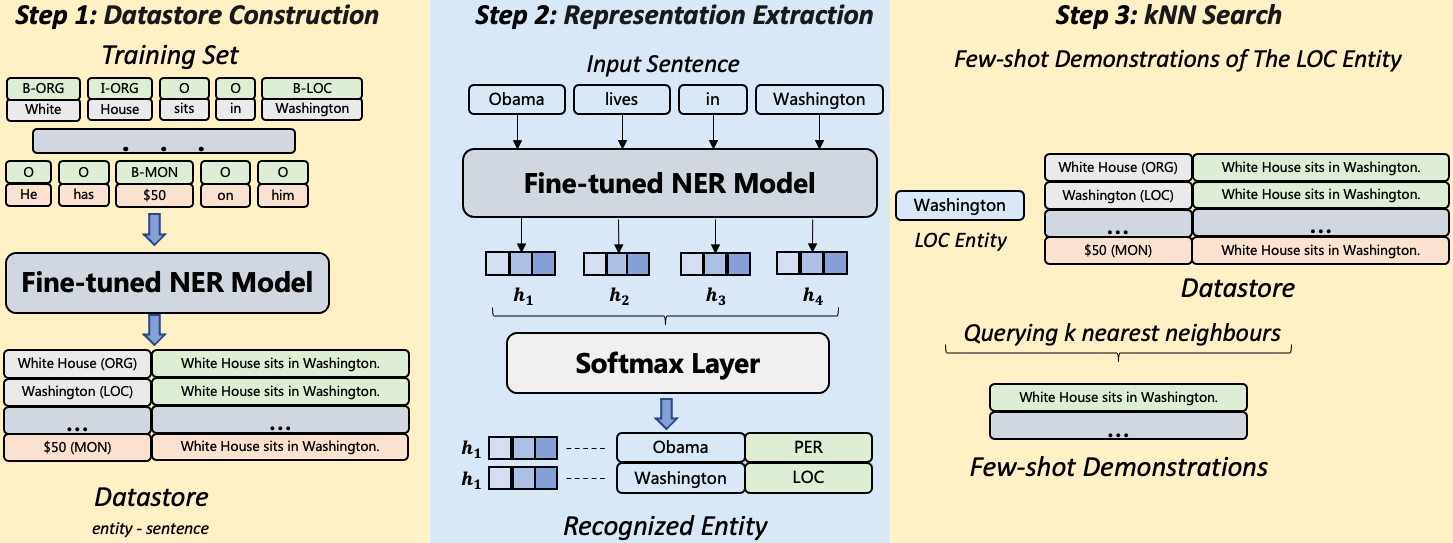
- 通过用特殊标记 @@ 和 ## 将实体包围,将 NER 转换为文本生成任务,从而生成带标签的序列。
- 用任务描述、少样例演示和输入句子段落来构建提示,以引导 LLM。
- 使用 token 级最近邻检索来获取演示示例,以提供相关示例。
- 引入自我验证步骤,在最终输出前模型检查提取的实体是否属于目标标签。
- 以 GPT-3 (davinci-003) 作为骨干模型,使用固定的生成设置,并在标准 NER 数据集上进行评估。

实验结果
研究问题
- RQ1带标记输出的 GPT 风格生成是否能在平坦和嵌套数据集上与有监督 NER 基线竞争?
- RQ2在 token 级 kNN 演示检索下,是否比随机或句子级检索能提升 NER 性能?
- RQ3自我验证步骤是否能减少幻觉并提高 NER 输出的准确性?
- RQ4在低资源和少样本场景中,GPT-NER 与有监督模型相比的表现如何?
- RQ5在演示检索中使用实体级嵌入对 NER 任务的影响是什么?
主要发现
- GPT-NER 在平坦 NER 数据集上达到与有监督基线相当的性能,在若干设置上接近 SOTA。
- 实体级(令牌感知)kNN 检索在演示示例方面显著优于随机与句子级检索。
- 自我验证通过缓解对 NULL 标签的过度自信标注带来额外收益并提升 F1 分数。
- GPT-NER 在低资源和少样本设置中显示出强大的优势,当标注数据稀缺时超过有监督模型。
- 在更大令牌预算下性能提升仍然存在,表明使用更高容量的 LLM(如 GPT-4)还有改进空间。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。