[论文解读] GPTAraEval: A Comprehensive Evaluation of ChatGPT on Arabic NLP
本论文对 ChatGPT (GPT-3.5-turbo) 在 44 个阿拉伯语 NLP 任务、跨越 60+ 个数据集上进行了大规模的自动和人工评估,结果显示 ChatGPT 相较于较小的微调阿拉伯语模型表现不佳,尤其在方言阿拉伯语上,GPT-4 通常优于 ChatGPT。
ChatGPT's emergence heralds a transformative phase in NLP, particularly demonstrated through its excellent performance on many English benchmarks. However, the model's efficacy across diverse linguistic contexts remains largely uncharted territory. This work aims to bridge this knowledge gap, with a primary focus on assessing ChatGPT's capabilities on Arabic languages and dialectal varieties. Our comprehensive study conducts a large-scale automated and human evaluation of ChatGPT, encompassing 44 distinct language understanding and generation tasks on over 60 different datasets. To our knowledge, this marks the first extensive performance analysis of ChatGPT's deployment in Arabic NLP. Our findings indicate that, despite its remarkable performance in English, ChatGPT is consistently surpassed by smaller models that have undergone finetuning on Arabic. We further undertake a meticulous comparison of ChatGPT and GPT-4's Modern Standard Arabic (MSA) and Dialectal Arabic (DA), unveiling the relative shortcomings of both models in handling Arabic dialects compared to MSA. Although we further explore and confirm the utility of employing GPT-4 as a potential alternative for human evaluation, our work adds to a growing body of research underscoring the limitations of ChatGPT.
研究动机与目标
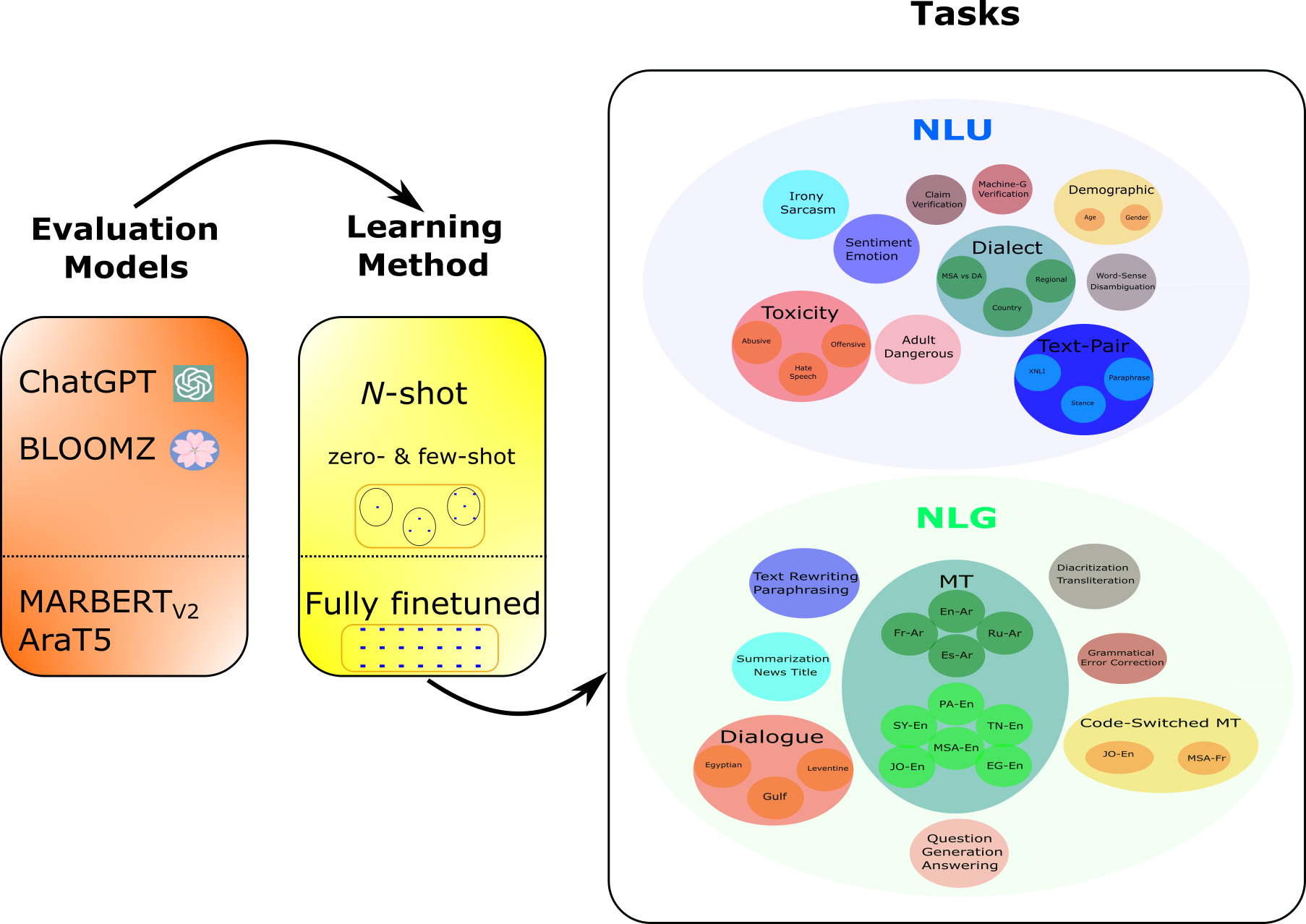
- 评估 ChatGPT 在广泛的阿拉伯语 NLU 和 NLG 任务及数据集上的表现。
- 将 ChatGPT 与 BLOOMZ 以及微调的阿拉伯语基线(MARBERT V2, AraT5)进行比较。
- 分析现代标准阿拉伯语(MSA)与方言阿拉伯语(DA)之间的性能差异。
- 评估基于人类评估与基于 GPT-4 的评估在阿拉伯语生成任务中的可靠性。
提出的方法
- 使用覆盖 60+ 数据集的 44 个阿拉伯语 NLP 任务用于 NLU 和 NLG。
- 在 0-, 3-, 5-, 10-shot 提示下对 ChatGPT (gpt-3.5-turbo-0301) 进行评估,使用英文通用提示模板。
- 与 BLOOMZ-7.1B(包含阿拉伯语微调)以及微调的 MARBERT V2 和 AraT5 基线进行比较。
- 对 NLU 使用 macro-F1,以及对 NLG 使用与任务相关的指标。
- 使用内置的 MSA vs DA 分类器和 ORCA 相关任务进行方言焦点评估,并在 DA 与 MSA 上比较 ChatGPT 与 GPT-4。
- 除了自动指标,还在八个 NLG 任务上进行人工评估,并将 GPT-4 作为评估基准。
实验结果
研究问题
- RQ1相对于阿拉伯语特定微调模型,ChatGPT 在广泛阿拉伯语NLP基准上的表现如何?
- RQ2相较于现代标准阿拉伯语,ChatGPT 是否在方言阿拉伯语上表现不佳?
- RQ3GPT-4 在包括方言变体在内的阿拉伯语 NLU/NLG 任务上是否始终优于 ChatGPT?
- RQ4GPT-4 是否能提供与人类判断一致的可靠自动评估,用于阿拉伯语生成任务?
主要发现
- 在大多数任务中,ChatGPT 通常劣于较小的微调阿拉伯语模型。
- MARBERT V2 在 NLU 任务上通常给出显著更高的 macro-F1 分数,超过 ChatGPT。
- 在方言阿拉伯语中,ChatGPT 的表现落后于 MSA,通常被 GPT-4 超越,GPT-4 在若干 DA 任务上表现更稳健。
- 在 NLG 任务上,AraT5 通常优于 ChatGPT 和 BLOOMZ,而 ChatGPT 在许多任务上超过 BLOOMZ,但仍低于 AraT5。
- 重述和一些文本对任务当增加 shot 时,ChatGPT 显示出显著提升,有时甚至超过完全微调的 MARBERT V2,尽管并非在所有任务上都稳定。
- GPT-4 对模型输出的评估在相当程度上与人类评估一致,表明 GPT-4 作为阿拉伯语生成任务的人类评估代理是可行的。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。