[论文解读] GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models
本文使用一种新的暴露评估标准,应用于 O*NET 任务数据,结合人类和 GPT-4 分类,估计大语言模型如何影响美国的工作任务和职业。结果显示广泛暴露,并在使用基于 LLM 的软件时获得显著提升。
We investigate the potential implications of large language models (LLMs), such as Generative Pre-trained Transformers (GPTs), on the U.S. labor market, focusing on the increased capabilities arising from LLM-powered software compared to LLMs on their own. Using a new rubric, we assess occupations based on their alignment with LLM capabilities, integrating both human expertise and GPT-4 classifications. Our findings reveal that around 80% of the U.S. workforce could have at least 10% of their work tasks affected by the introduction of LLMs, while approximately 19% of workers may see at least 50% of their tasks impacted. We do not make predictions about the development or adoption timeline of such LLMs. The projected effects span all wage levels, with higher-income jobs potentially facing greater exposure to LLM capabilities and LLM-powered software. Significantly, these impacts are not restricted to industries with higher recent productivity growth. Our analysis suggests that, with access to an LLM, about 15% of all worker tasks in the US could be completed significantly faster at the same level of quality. When incorporating software and tooling built on top of LLMs, this share increases to between 47 and 56% of all tasks. This finding implies that LLM-powered software will have a substantial effect on scaling the economic impacts of the underlying models. We conclude that LLMs such as GPTs exhibit traits of general-purpose technologies, indicating that they could have considerable economic, social, and policy implications.
研究动机与目标
- 促使理解 LLMs(GPTs)如何超越模型能力本身影响劳动力市场。
- 开发并应用一个评估标准,使用人类和 GPT-4 分类来衡量对 LLM 的任务暴露。
- 将任务层面的暴露聚合为职业和行业层面的洞见。
- 强调互补技术和 LLM 驱动软件在放大经济影响中的作用。
提出的方法
- 使用 O*NET 的 DWA 和任务(19,265 个任务;2,087 个 DWA)构建任务-职业层面的暴露度量。
- 在 50% 时间减少评分标准下,使用人类判断和 GPT-4 分类对暴露进行标注。
- 定义三种暴露度量:alpha (E1)、beta (E1 + 0.5*E2) 和 zeta (E1 + E2)。
- 将核心任务在聚合到职业时的权重设为核心任务的两倍于补充任务。
- 比较人类和 GPT-4 的标注,并评估在职业层面的一致性和相关性。
实验结果
研究问题
- RQ1有多少比例的美国职业在任务层面对 LLM 有暴露?
- RQ2人类评估者与 GPT-4 分类之间的暴露估计有何差异?
- RQ3仅使用 LLM 与使用 LLM 驱动的软件对任务完成时间的影响有何不同?
- RQ4暴露模式如何因职业、工资水平和行业而异?
主要发现
- 约 80% 的工人属于至少有 10% 的任务暴露给 LLM 的职业(beta 指标)。
- 约 19% 的工人处于至少 50% 的任务暴露给 LLM 的职业(beta 指标)。
- 平均而言,使用单独的 LLM 可显著更快完成大约 15% 的所有工人任务;若使用 LLM 驱动的软件,这一比例上升至 47–56%。
- 职业层面的平均 alpha 值约为 0.14–0.15;beta 约为 0.30(人类)和 0.34(GPT-4);zeta 更高,说明跨职业存在相当大的潜在暴露。
- 暴露倾向于在高薪工作和信息处理行业中更高;暴露与编程和写作技能相关,而与科学/批判性思维技能呈负相关。
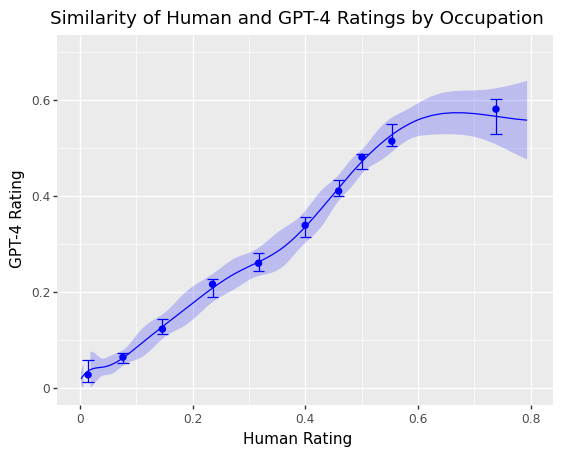
- 在职业层面关于对 LLM 系统暴露的标注方面,人类与 GPT-4 之间存在显著的一致性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。