[论文解读] graph2vec: Learning Distributed Representations of Graphs
graph2vec 通过将带根的子图视为文档中的词来学习整个图的无监督、数据驱动嵌入,促进图分类和聚类,性能可与图核相媲美。
Recent works on representation learning for graph structured data predominantly focus on learning distributed representations of graph substructures such as nodes and subgraphs. However, many graph analytics tasks such as graph classification and clustering require representing entire graphs as fixed length feature vectors. While the aforementioned approaches are naturally unequipped to learn such representations, graph kernels remain as the most effective way of obtaining them. However, these graph kernels use handcrafted features (e.g., shortest paths, graphlets, etc.) and hence are hampered by problems such as poor generalization. To address this limitation, in this work, we propose a neural embedding framework named graph2vec to learn data-driven distributed representations of arbitrary sized graphs. graph2vec's embeddings are learnt in an unsupervised manner and are task agnostic. Hence, they could be used for any downstream task such as graph classification, clustering and even seeding supervised representation learning approaches. Our experiments on several benchmark and large real-world datasets show that graph2vec achieves significant improvements in classification and clustering accuracies over substructure representation learning approaches and are competitive with state-of-the-art graph kernels.
研究动机与目标
- 在整个图上学习固定长度嵌入以促进下游 ML 任务,如分类和聚类的动机与目标。
- 通过提出一种数据驱动、无监督、任务无关的方法来解决手工制图核与子结构嵌入的局限性。
- 借鉴文档嵌入的思路将图建模为带根子图的文档。
- 在基准数据集和大规模真实数据(恶意软件图)上在分类和聚类任务中展示有效性。
提出的方法
- 将每个图表示为以节点为中心、包含最多 D 阶的带根子图组成的文档。
- 使用 WL 重标签化生成并将带根子图标注为词汇项。
- 训练带负采样的 skipgram 模型以学习图嵌入,优化 Pr(sg|G)。
- 通过随机梯度下降在多个时期迭代更新图嵌入。
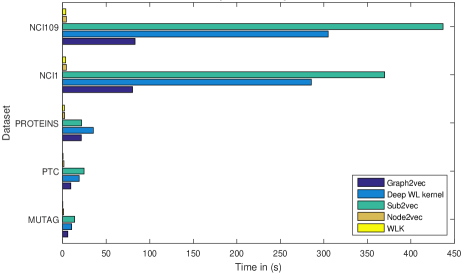
- 在多个数据集上将 graph2vec 与 node2vec、sub2vec、WL 核、Deep WL 核进行对比。
- 使用一个无监督、任务无关的目标将图嵌入为固定维度 delta。
实验结果
研究问题
- RQ1graph2vec 在准确性和效率方面相对于最先进的子结构表示学习方法和图核,在基准数据集上的图分类表现如何?
- RQ2graph2vec 在大规模真实世界图分类任务(如恶意软件检测)上相对于现有方法的表现如何?
- RQ3graph2vec 在图聚类任务(如恶意软件家族聚类)相对于竞争方法的表现如何?
主要发现
| Dataset | node2vec | sub2vec | WL kernel | Deep WL kernel | graph2vec |
|---|---|---|---|---|---|
| MUTAG | 72.63 \u0000b1 10.20 | 61.05 \u0000b1 15.79 | 80.63 \u0000b1 3.07 | 82.95 \u0000b1 1.96 | 83.15 \u0000b1 9.25 |
| PTC | 58.85 \u0000b1 8.00 | 59.99 \u0000b1 6.38 | 56.91 \u0000b1 2.79 | 59.04 \u0000b1 1.09 | 60.17 \u0000b1 6.86 |
| PROTEINS | 57.49 \u0000b1 3.57 | 53.03 \u0000b1 5.55 | 72.92 \u0000b1 0.56 | 73.30 \u0000b1 0.82 | 73.30 \u0000b1 2.05 |
| NCI1 | 54.89 \u0000b1 1.61 | 52.84 \u0000b1 1.47 | 80.01 \u0000b1 0.50 | 80.31 \u0000b1 0.46 | 73.22 \u0000b1 1.81 |
| NCI109 | 52.68 \u0000b1 1.56 | 50.67 \u0000b1 1.50 | 80.12 \u0000b1 0.34 | 80.32 \u0000b1 0.33 | 74.26 \u0000b1 1.47 |
- 在基准数据集上,graph2vec 在 MUTAG、PTC 和 PROTEINS 上优于其他表示学习和核方法,在 NCI1 和 NCI109 上具有可比精度。
- 在大规模真实世界的恶意软件分类中,graph2vec 的准确率达到 99.03%,优于 node2vec、sub2vec、WL 核和 Deep WL 核。
- Sub2vec 在大多数数据集上通常因采样限制而表现不佳;node2vec 在较大图上表现不佳;WL 核仍为强基线,与 graph2vec 之间存在具有竞争力的差距。
- Graph2vec 提供一种数据驱动、保持结构的表示,能够捕捉局部和全局的图相似性。
- 嵌入可以与通用分类器(RF、NN、SVM)一起用于图分类和聚类,而不是某些基于核的方法。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。