[论文解读] Hallucination Mitigation using Agentic AI Natural Language-Based Frameworks
这篇论文提出一个基于多代理与 NLP 的工作流,使用 OVON 框架在三个评审阶段检测、标注并改进大型语言模型输出中的错觉,提高错觉分数的降低。
Hallucinations remain a significant challenge in current Generative AI models, undermining trust in AI systems and their reliability. This study investigates how orchestrating multiple specialized Artificial Intelligent Agents can help mitigate such hallucinations, with a focus on systems leveraging Natural Language Processing (NLP) to facilitate seamless agent interactions. To achieve this, we design a pipeline that introduces over three hundred prompts, purposefully crafted to induce hallucinations, into a front-end agent. The outputs are then systematically reviewed and refined by second- and third-level agents, each employing distinct large language models and tailored strategies to detect unverified claims, incorporate explicit disclaimers, and clarify speculative content. Additionally, we introduce a set of novel Key Performance Indicators (KPIs) specifically designed to evaluate hallucination score levels. A dedicated fourth-level AI agent is employed to evaluate these KPIs, providing detailed assessments and ensuring accurate quantification of shifts in hallucination-related behaviors. A core component of this investigation is the use of the OVON (Open Voice Network) framework, which relies on universal NLP-based interfaces to transfer contextual information among agents. Through structured JSON messages, each agent communicates its assessment of the hallucination likelihood and the reasons underlying questionable content, thereby enabling the subsequent stage to refine the text without losing context. The results demonstrate that employing multiple specialized agents capable of interoperating with each other through NLP-based agentic frameworks can yield promising outcomes in hallucination mitigation, ultimately bolstering trust within the AI community.
研究动机与目标
- 解决生成式 AI LLM 的错觉挑战。
- 提出一个多代理管线,通过专业评审实现对输出的迭代改进。
- 引入新的 KPI 以量化错觉缓解和可解释性。
提出的方法
- 向前端代理注入 310 条旨在诱发错觉的提示。
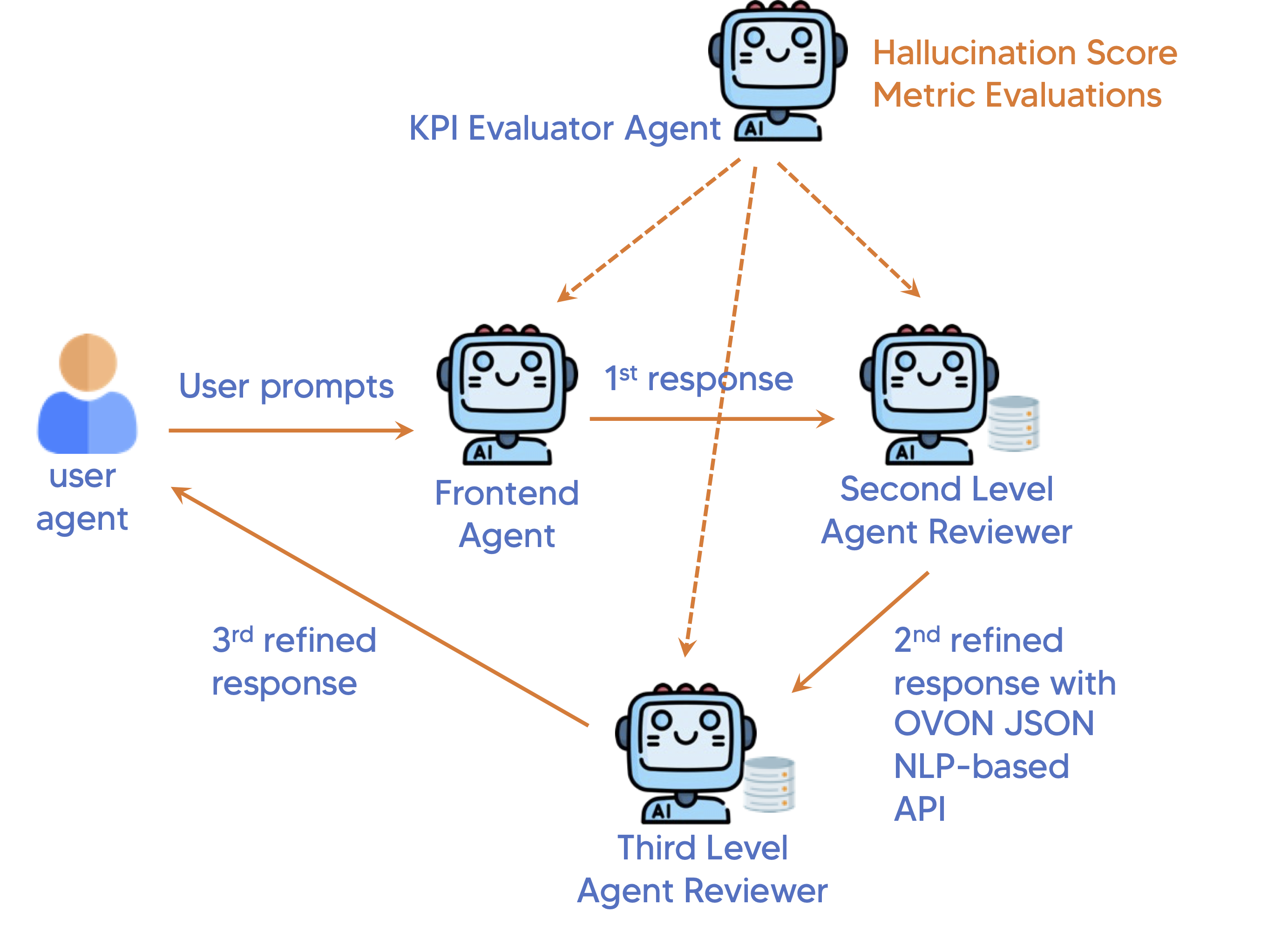
- 使用二级和三级代理(配备 GPT-4o)通过 OVON JSON 消息检测、免责声明与改进主张。
- 使用第四个代理评估 KPIs 并量化错觉变化(THS)。
- 通过 OVON 的 Conversation Envelopes( utterance 与 whisper 事件)促进代理间通信。
- 以 Autogen 基于的代理框架进行编排以实现迭代改进。
实验结果
研究问题
- RQ1多代理、基于 NLP 的框架是否能够降低 LLM 输出中的错觉可能性?
- RQ2基于 OVON 的代理间通信如何影响信息流动与改进?
- RQ3哪些 KPI 最能量化事实性、落地性以及对虚构内容的明确信号?
- RQ4第三层评审是否在事实性与免责声明效果上超越二层评审?
主要发现
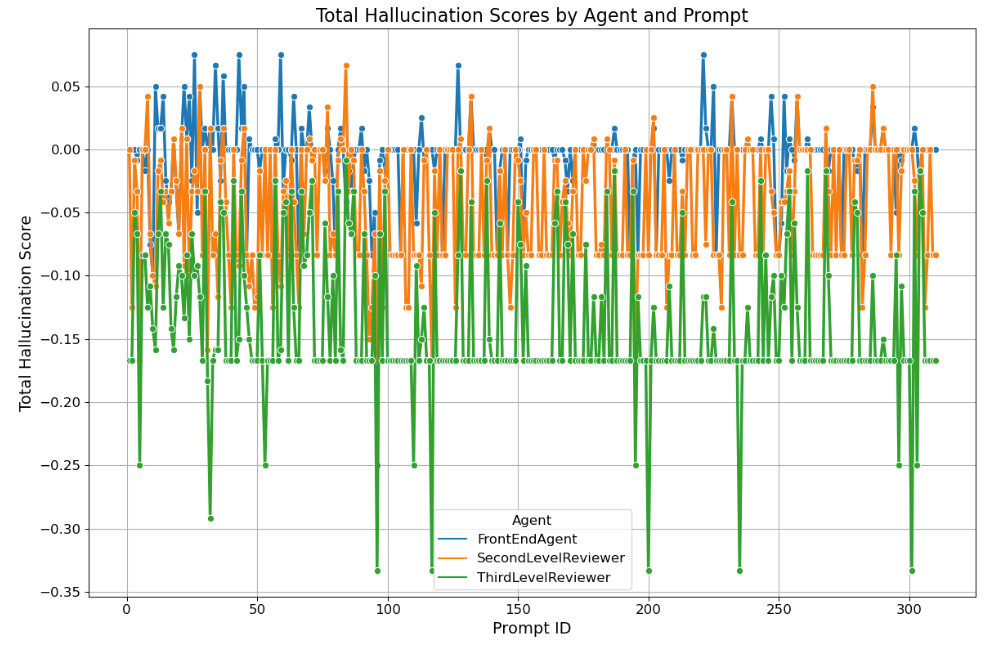
- 多代理管线在各阶段(前端→二级评审→三级评审)逐步降低错觉分数。
- 新 KPI(事实性主张密度、事实性落地引用、虚构免责声明频率、明确情境化分数)能够有效量化错觉缓解。
- 专门的第四个代理能够对 KPI 变化和总错觉分数(THS)提供量化评估。
- 基于 OVON 的 JSON 消息在保持上下文的同时实现跨代理的针对性改进,提升可解释性与可靠性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。