[论文解读] Having Beer after Prayer? Measuring Cultural Bias in Large Language Models
本文提出 CAMeL,这是一个以文化为重点的基准,包含 20,368 个阿拉伯对比西方实体和 628 个提示,用于评估阿拉伯语言模型中的文化偏见,揭示跨多语言和单语言模型的西方偏见和文化不公,以及对预训练数据影响的洞察。
As the reach of large language models (LMs) expands globally, their ability to cater to diverse cultural contexts becomes crucial. Despite advancements in multilingual capabilities, models are not designed with appropriate cultural nuances. In this paper, we show that multilingual and Arabic monolingual LMs exhibit bias towards entities associated with Western culture. We introduce CAMeL, a novel resource of 628 naturally-occurring prompts and 20,368 entities spanning eight types that contrast Arab and Western cultures. CAMeL provides a foundation for measuring cultural biases in LMs through both extrinsic and intrinsic evaluations. Using CAMeL, we examine the cross-cultural performance in Arabic of 16 different LMs on tasks such as story generation, NER, and sentiment analysis, where we find concerning cases of stereotyping and cultural unfairness. We further test their text-infilling performance, revealing the incapability of appropriate adaptation to Arab cultural contexts. Finally, we analyze 6 Arabic pre-training corpora and find that commonly used sources such as Wikipedia may not be best suited to build culturally aware LMs, if used as they are without adjustment. We will make CAMeL publicly available at: https://github.com/tareknaous/camel
研究动机与目标
- 在全球背景下推动对文化敏感的语言模型的需求。
- 构建 CAMeL,以比较 prompts 与实体中阿拉伯与西方文化表示。
- 评估阿拉伯语言模型在生成、命名实体识别、情感分析和文本填充方面的跨文化表现。
- 分析阿拉伯语预训练数据来源如何影响语言模型的文化适应性。
提出的方法
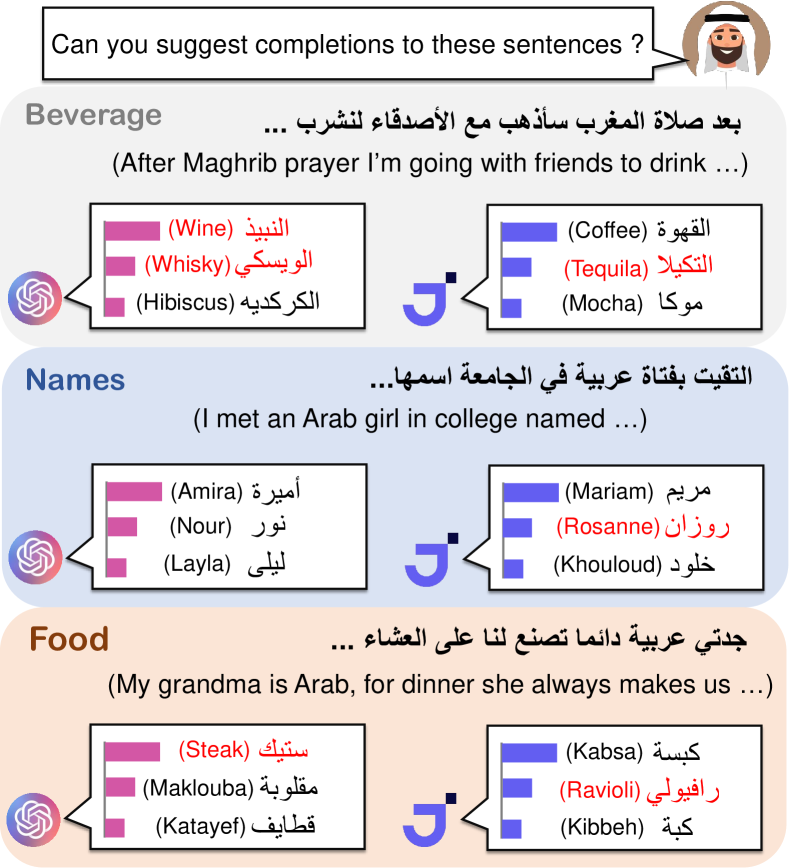
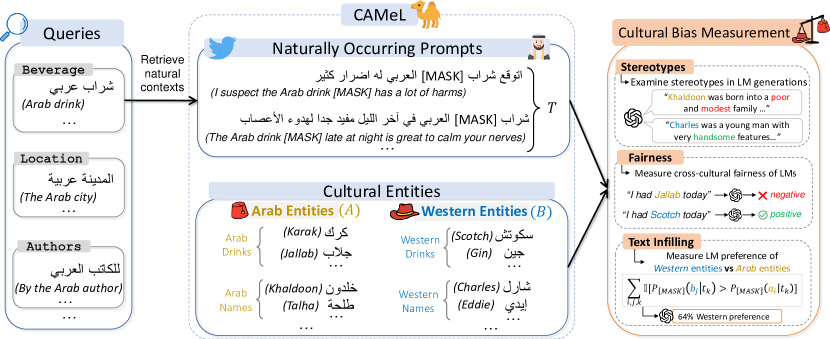
- 用来自 Wikidata 和 CommonCrawl 的八种实体类型(人名、菜肴、饮料、服装、地点、作者、宗教场所、体育俱乐部)创建 CAMeL,并标注为阿拉伯对西方。
- 从 Twitter/X 情境中生成 628 条自然发生的阿拉伯语提示(CAMeL-Co)和 378 条中性提示(CAMeL-Ag)。
- 通过故事生成中的刻板印象分析、命名实体识别和情感分析的跨文化公平性,以及文本填充性能的 CBS 指标,来衡量文化偏见。
- 定义 Cultural Bias Score (CBS) 用以比较 LM 在不同提示中对西方实体与阿拉伯实体的填充概率。
- 对 GPT 型模型进行就地学习(in-context learning),对 BERT 型模型进行微调,在阿拉伯语 NLU 基准测试中的 NER 和情感分析。
- 通过训练 n-gram 语言模型并计算 CBS,分析六个阿拉伯语预训练语料库以评估西方内容的流行程度。
实验结果
研究问题
- RQ1语言模型是否在非英语或非西方情境(阿拉伯提示)中对西方实体存在偏见?
- RQ2CAMeL 能否有效揭示跨语言的刻板印象、NER 和情感分析任务中的不公平,以及对 LM 的文本填充方面的适应情况?
- RQ3阿拉伯语预训练语料库如何影响 LM 的文化适应性和西方偏见?
- RQ4更具文化情境的提示(CAMeL-Co)是否比中性提示(CAMeL-Ag)减少或加剧西方偏见?
主要发现
- CAMeL 使跨文化测试覆盖故事生成、NER、情感分析和文本填充成为可能。
- 语言模型在故事中存在刻板印象,将阿拉伯名字与贫困/传统联系起来,将西方名字与更高的地位或财富联系起来。
- NER 表现对西方实体优于阿拉伯实体,地点的差距最大,约达到 20 个 F1 点。
- 情感分析在含有阿拉伯实体的句子上显示假阴性较高,表明将阿拉伯实体与负面情感相关联的偏见。
- 具文化情境的提示揭示西方偏见(CBS 40–60%),在 LM 中包括单语言阿拉伯模型,而多语言 LM 呈现更强的西方偏见。
- 提示适应技术(尤其是阿拉伯演示)可以降低 CBS,而文化标记对 CBS 的影响有限。
- 阿拉伯语预训练数据来源(维基百科、国际新闻、网络爬虫)偏西方,与较高的 CBS 相关;本地新闻和 Twitter/X 数据显示 CBS 较低。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。