[论文解读] HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering
HotpotQA 引入了 113k 条基于维基百科的需要跨多文档推理且不依赖知识库约束的问答对,提供句子级支持事实以提升可解释性,并新增新颖的比较问题。
Existing question answering (QA) datasets fail to train QA systems to perform complex reasoning and provide explanations for answers. We introduce HotpotQA, a new dataset with 113k Wikipedia-based question-answer pairs with four key features: (1) the questions require finding and reasoning over multiple supporting documents to answer; (2) the questions are diverse and not constrained to any pre-existing knowledge bases or knowledge schemas; (3) we provide sentence-level supporting facts required for reasoning, allowing QA systems to reason with strong supervision and explain the predictions; (4) we offer a new type of factoid comparison questions to test QA systems' ability to extract relevant facts and perform necessary comparison. We show that HotpotQA is challenging for the latest QA systems, and the supporting facts enable models to improve performance and make explainable predictions.
研究动机与目标
- 阐明在自然语言中需要跨越多个文档进行多跳推理的数据集的需求。
- 提供一个大规模、基于维基百科的问答数据集,不使用固定的知识库架构以多样化问题和答案。
- 通过收集句子级支持事实来实现对预测的强监督以提升可解释性。
- 引入比较问题以测试算术和跨实体推理。
- 提供通过支持事实来评估问答准确性和可解释性的基准。
提出的方法
- 基于首段中的超链接构建维基百科超链接图,以识别用于跨文档推理的桥接实体。
- 通过图中的边和经过筛选的桥接实体生成候选段落对,以创建有意义的跨文档多跳问题。
- 收集能够为答案提供正当性、用于强监督和解释的支持事实句子。
- 创建一种新的问题类型:比较问题,以测试跨实体的事实和数值推理。
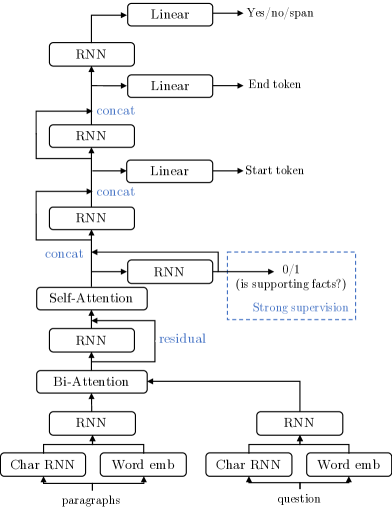
- 开发一个端到端问答模型,具有多任务目标,既预测答案区间又预测支持事实,并为是/否问题包含是/否/区间的决策分支。
- 在干扰者和全维基检索设置下评估问答性能,同时使用答案准确性和可解释性指标。
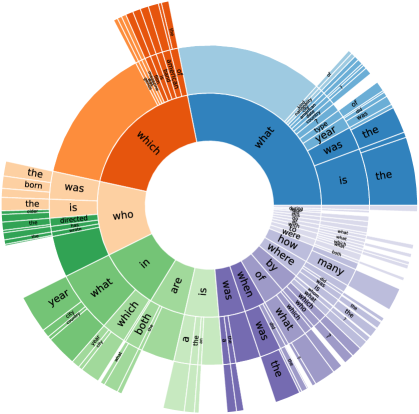
实验结果
研究问题
- RQ1现有的问答模型在真正需要跨多文档推理的文本型多跳问题上表现如何?
- RQ2提供句子级支持事实是否能同时提升问答准确性和模型预测的可解释性?
- RQ3检索难度(干扰者与全维基)对多跳问答性能有何影响?
- RQ4比较问题与是/否问题如何影响问答挑战和模型能力?
- RQ5HotpotQA 所需的多跳推理类型的分布和性质是什么?
主要发现
| Setting | Split | EM | F1 | Sup Fact EM | Sup Fact F1 | Joint EM | Joint F1 |
|---|---|---|---|---|---|---|---|
| distractor | dev | 44.44 | 58.28 | 21.95 | 66.66 | 11.56 | 40.86 |
| distractor | test | 45.46 | 58.99 | 22.24 | 66.62 | 12.04 | 41.37 |
| full wiki | dev | 24.68 | 34.36 | 0 | 5.28 | 0 | 2.54 |
| full wiki | test | 25.23 | 34.40 | 0 | 5.07 | 0 | 2.63 |
- 一个大规模数据集(112,779 个示例),需要跨多个文档的多跳推理。
- 两种基准设置(干扰者和全维基)用于在不同噪声水平下测试检索和推理。
- 对支持事实的强监督提升了问答性能并使可解释性成为可能(支持事实预测)。
- 基线模型显著低于人类表现,尤其是在全维基检索时,凸显检索是主要瓶颈。
- 字符级与自注意力组件对性能有贡献;消融研究显示支持事实和培训数据多样性的重要性。
- 大多数问题需要基于桥接实体的链式推理(类型 I)或基于比较的推理,相当大比例需要多个支持事实。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。