[论文解读] How Far Can Camels Go? Exploring the State of Instruction Tuning on Open Resources
本文系统评估跨6.7B–65B参数的模型大小和基础LM的开源指令微调数据集,结果表明没有单一数据集在所有任务上都最佳,基础模型质量至关重要,而他们的最佳开源模型(Tülu)在平均水平上落后于 ChatGPT/GPT-4。作者发布了模型、数据和评估框架。
In this work we explore recent advances in instruction-tuning language models on a range of open instruction-following datasets. Despite recent claims that open models can be on par with state-of-the-art proprietary models, these claims are often accompanied by limited evaluation, making it difficult to compare models across the board and determine the utility of various resources. We provide a large set of instruction-tuned models from 6.7B to 65B parameters in size, trained on 12 instruction datasets ranging from manually curated (e.g., OpenAssistant) to synthetic and distilled (e.g., Alpaca) and systematically evaluate them on their factual knowledge, reasoning, multilinguality, coding, and open-ended instruction following abilities through a collection of automatic, model-based, and human-based metrics. We further introduce Tülu, our best performing instruction-tuned model suite finetuned on a combination of high-quality open resources. Our experiments show that different instruction-tuning datasets can uncover or enhance specific skills, while no single dataset (or combination) provides the best performance across all evaluations. Interestingly, we find that model and human preference-based evaluations fail to reflect differences in model capabilities exposed by benchmark-based evaluations, suggesting the need for the type of systemic evaluation performed in this work. Our evaluations show that the best model in any given evaluation reaches on average 87% of ChatGPT performance, and 73% of GPT-4 performance, suggesting that further investment in building better base models and instruction-tuning data is required to close the gap. We release our instruction-tuned models, including a fully finetuned 65B Tülu, along with our code, data, and evaluation framework at https://github.com/allenai/open-instruct to facilitate future research.
研究动机与目标
- 评估在开源数据集上进行指令微调如何影响模型在事实知识、推理、多语言能力、编码、安全性以及对开放式指令的执行等方面的能力。
- 比较在广泛的基础模型和指令数据集上的性能,以识识别常用于开源指令微调的资源的优缺点。
- 调查基于模型的评估与基准评估在揭示模型能力方面是否一致。
- 提出并评估一个基于多样化开源资源构建的最佳表现开源指令微调模型套件(Tülu)。
提出的方法
- 将多样化的指令数据集合并为统一的聊天机器人风格格式,以对解码器为主的语言模型进行教师强制训练并进行逐-token损失屏蔽。
- 在基礎模型(LLaMa、LLaMa-2、OPT、Pythia)和大小范围(6.7B–65B)上,使用涵盖手工、合成和蒸馏来源的12个指令数据集进行训练。
- 创建两种数据混合方式(Human 数据,以及 Human+GPT 数据)来训练 Tülu 模型并比较混合效果。
- 使用包括 MMLU、GSM、BBH、TyDiQA、Codex-Eval、AlpacaEval、ToxiGen、TruthfulQA 的多元评估套件进行模型评估,外加基于模型的(GPT-4 标注者)评估和人工评估。
- 分析数据集选择、基础模型质量和数据混合如何影响跨任务和评估方式的性能。

实验结果
研究问题
- RQ1如何指令微调数据集影响模型在事实知识、推理、跨语言能力、编码以及对开放式指令执行等方面的具体技能?
- RQ2将多样化数据集结合起来是否能带来总体最佳性能,还是在某些评估中任务特定数据集占主导?
- RQ3基础模型的质量(大小和预训练数据)如何与指令微调数据交互影响性能?
- RQ4基于模型的评估与基准评估在反映模型能力方面是否与之保持一致?
- RQ5在各种评估设置下,开源指令微调模型与专有模型(ChatGPT、GPT-4)之间的性能差距是多少?
主要发现
- 不同的指令数据集提升了不同的能力;没有单一数据集在所有任务上都表现出色。
- 较大的基础模型在指令微调后通常表现更好,基础模型质量是一个主导因素。
- 高质量开源数据集(Tülu)的混合在基准测试上实现了最佳平均性能,但在他们设定中平均并未超越 ChatGPT 或 GPT-4。
- 即使是在多样化数据上微调的65B开源模型也仍然落后于专有模型,凸显仍存的差距。
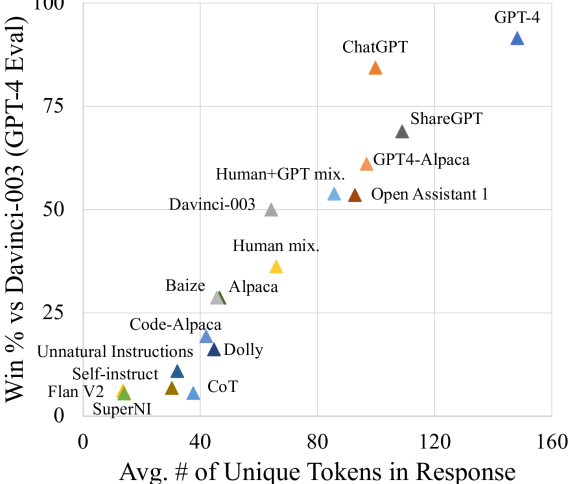
- 基于模型的偏好信号与生成长度相关,而非真实能力,提示此类评估存在偏差。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。