[论文解读] How Good Are GPT Models at Machine Translation? A Comprehensive Evaluation
论文在18对语言方向上评估 GPT 模型(ChatGPT、text-davinci-003、text-davinci-002)的机器翻译表现,显示高资源语言的强劲性能、低资源语言的能力有限,以及通过 prompting 策略、文档级翻译和混合 GPT+NMT 方法带来的潜在收益。
Generative Pre-trained Transformer (GPT) models have shown remarkable capabilities for natural language generation, but their performance for machine translation has not been thoroughly investigated. In this paper, we present a comprehensive evaluation of GPT models for machine translation, covering various aspects such as quality of different GPT models in comparison with state-of-the-art research and commercial systems, effect of prompting strategies, robustness towards domain shifts and document-level translation. We experiment with eighteen different translation directions involving high and low resource languages, as well as non English-centric translations, and evaluate the performance of three GPT models: ChatGPT, GPT3.5 (text-davinci-003), and text-davinci-002. Our results show that GPT models achieve very competitive translation quality for high resource languages, while having limited capabilities for low resource languages. We also show that hybrid approaches, which combine GPT models with other translation systems, can further enhance the translation quality. We perform comprehensive analysis and human evaluation to further understand the characteristics of GPT translations. We hope that our paper provides valuable insights for researchers and practitioners in the field and helps to better understand the potential and limitations of GPT models for translation.
研究动机与目标
- 评估 GPT 模型在高资源语言和低资源语言上的翻译质量。
- 探索 prompting 策略(零-shot、少量-shot)及其对翻译性能的影响。
- 评估文档级翻译能力及在领域转移下的鲁棒性。
- 将 GPT 模型与最先进的研究和商业系统进行对比。
- 研究将 GPT 与传统 NMT 系统结合的潜在益处。
提出的方法
- 将 GPT 变体(text-davinci-002、text-davinci-003、ChatGPT)在18对语言对上与 WMT-Best 和 Microsoft Translator 进行比较。
- 使用零-shot 和少量-shot 提示评估上下文学习效果。
- 采用神经 MT 指标(COMET-22、COMETkiwi)与词汇指标(BLEU、ChrF)进行评估,并进行文档级适配(Doc-COMETkiwi)。
- 通过滑动窗口重叠将 COMET-kiwi 调整用于文档级评估(Doc-COMETkiwi)。
- 进行人工评估以补充基于指标的评估。
- 分析提示设计(质量和相关性)及其对翻译结果的影响。
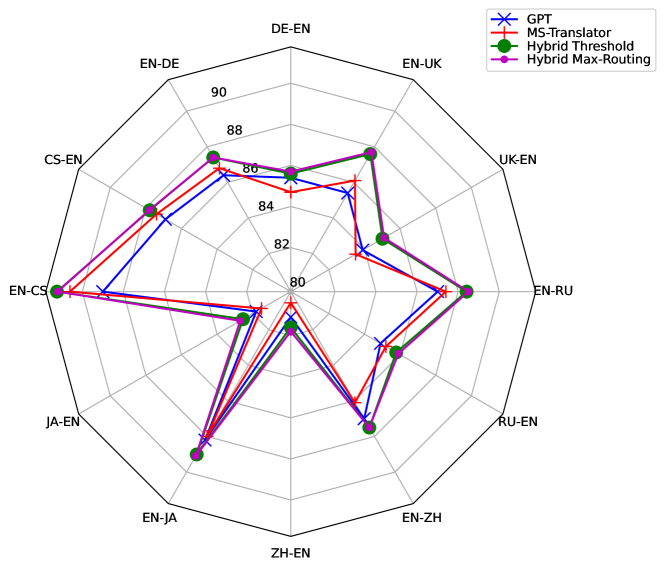
实验结果
研究问题
- RQ1GPT 模型在机器翻译中的表现如何,与最先进的研究和商业系统在多样化语言对上的比较如何?
- RQ2 prompting 策略(零-shot vs 少-shot、拍摄质量和相关性)对 GPT 翻译质量有何影响?
- RQ3GPT 模型在文档级翻译中能否有效工作,且上下文如何影响表现?
- RQ4GPT 翻译对领域转移的鲁棒性如何,是否能和非英语为中心的翻译协同工作,GPT 是否能补充传统 NMT 系统?
- RQ5与 NMT 相比,GPT 翻译的特征与局限性是什么,包括伪影和潜在的跨语言优势?
主要发现
- GPT 模型在高资源语言上实现了非常具竞争力的翻译质量,但在低资源语言上能力受限。
- 提示策略,特别是少-shot 的高质量示例,在某些方向上可以提升性能,尤其是从英语翻译到其他语言时。
- 通过 GPT 进行文档级翻译可以利用更广的上下文,并在适当的评估下,可以接近或超过某些基线系统,视指标而定。
- 将 GPT 模型与传统 NMT 系统结合的混合方法可以进一步提升翻译质量。
- 人工评估和详细分析揭示了 GPT 翻译的优点和弱点,并提供了伪影模式与跨语言行为的见解。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。