[论文解读] How well do Large Language Models perform in Arithmetic tasks?
本文介绍 MATH 401,一个用于评估大型语言模型在多样运算中的数值计算能力的算术数据集;结果显示 GPT-4 与 ChatGPT 实现最高精度,并分析分词、预训练、提示和扩展等因素。
Large language models have emerged abilities including chain-of-thought to answer math word problems step by step. Solving math word problems not only requires abilities to disassemble problems via chain-of-thought but also needs to calculate arithmetic expressions correctly for each step. To the best of our knowledge, there is no work to focus on evaluating the arithmetic ability of large language models. In this work, we propose an arithmetic dataset MATH 401 to test the latest large language models including GPT-4, ChatGPT, InstrctGPT, Galactica, and LLaMA with various arithmetic expressions and provide a detailed analysis of the ability of large language models. MATH 401 and evaluation codes are released at \url{https://github.com/GanjinZero/math401-llm}.
研究动机与目标
- 激励需要将算术能力作为衡量 LLMs 数学与推理能力的代理的原因。
- 介绍 MATH 401,一个覆盖整数、小数、无理数和长表达式的算术评估套件。
- 分析架构选择和训练数据如何影响 LLM 的算术表现。
- 提供关于提示、系统消息和提示策略以提升算术结果的指导。
提出的方法
- 构造覆盖四则运算、乘法、除法、幂运算、三角、对数以及长括号表达式的 401 个算术表达式。
- 在不同提示与输入格式下评估广泛的 LLMs(GPT-4、ChatGPT、InstructGPT、Galactica、LLaMA、OPT、Bloom 等)。
- 以准确率、相对误差和非数字比率为指标,四位小数四舍五入并对解码数字做特定处理。
- 比较分词效应、预训练数据(代码和 LaTeX 源)、指令微调与 RLHF 对算术性能的影响。
- 研究插值/外推、缩放定律、思维链(COT)效应与上下文学习(ICL) 对算术任务的影响。
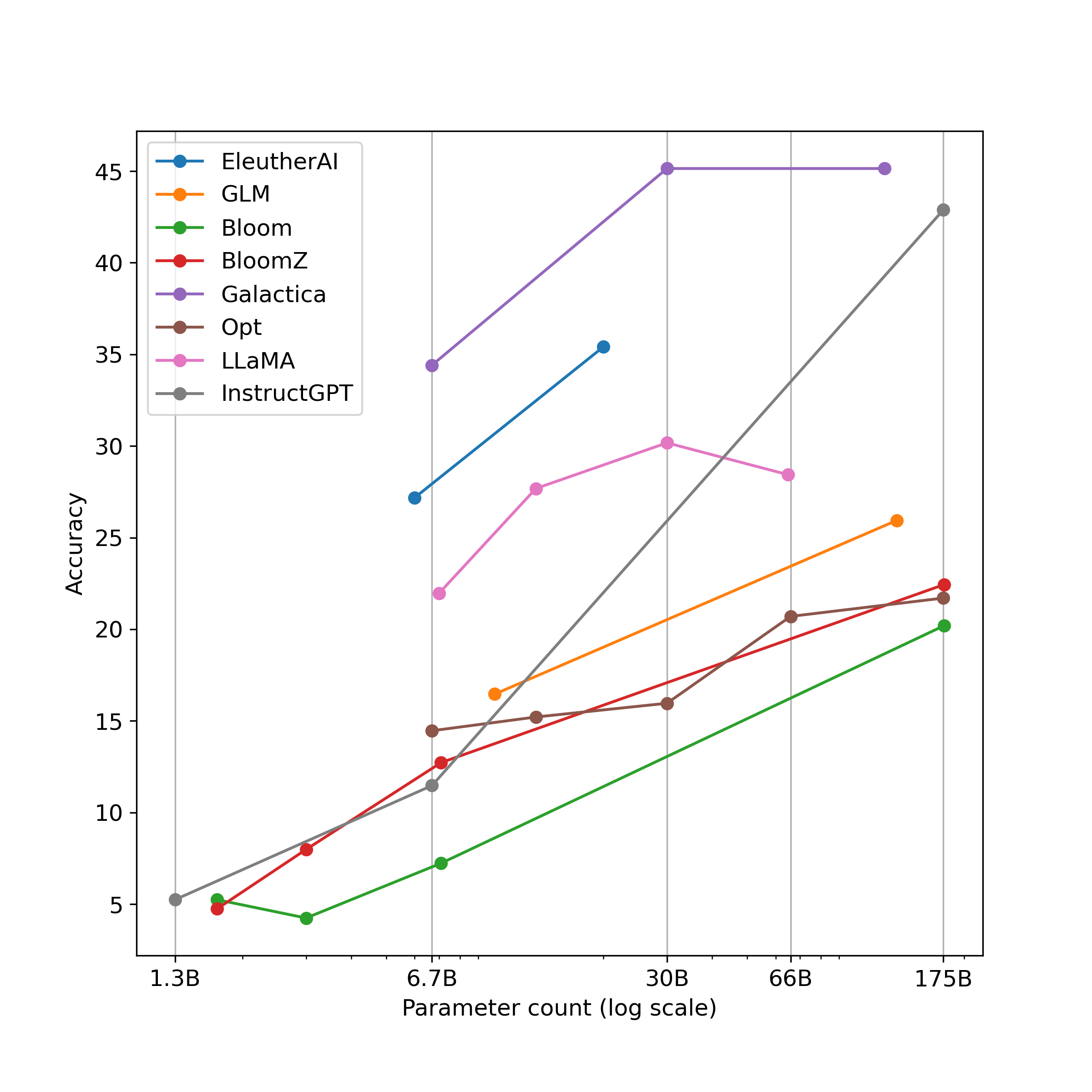
实验结果
研究问题
- RQ1当前大型语言模型在涵盖各类运算符和数值形式的算术任务中有多大能力?
- RQ2哪些因素(分词、训练数据、提示、扩展)影响 LLM 的算术表现?
- RQ3思维链提示或系统级提示是否能显著提升算术准确性?
- RQ4指令微调与 ICL 能否显著提升算术能力,模型大小如何影响结果?
- RQ5模型在简单与困难的算术组上的表现如何,并能否外推到长表达式?
主要发现
- GPT-4 与 ChatGPT 在所有算术任务上显著优于其他模型。
- 对多数模型而言,除法、带小数的幂运算、三角和对数仍具挑战性;大数字和长表达式由 GPT-4 与 ChatGPT 处理更好。
- 分词策略(如按数字位级别或分割标记)显著影响算术准确性;将数字分成数字位的模型通常表现不同。
- 指令微调和 RLHF(如 InstructGPT 与 ChatGPT)相对于较早的预训练或 SFT 模型提高算术能力。
- 提示很重要:LaTeX 或数学文本提示对许多模型通常带来更好结果;系统提示显著提升 ChatGPT 的准确性并减少非数字解码。
- COT 提示并不始终提升算术表现;简单的计算提示有时对长表达式更有利。
- 扩展有帮助但到一定程度;超过大约 30B 参数后,一些模型(如 Galactica)增益趋于平稳,而 GPT-4/ChatGPT 在长表达式上显示强大能力。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。