[论文解读] HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units
HuBERT 提出了一种自监督语音表征学习方法,通过从掩码语音特征中预测 K-means 聚类单元来实现,利用离线聚类步骤生成伪标签。通过仅在掩码区域上应用预测损失,该方法学习到鲁棒的语音与语言表征,在 1B 参数模型下,Librispeech dev-other 上实现了高达 19% 的 WER 降低,test-other 上实现了 13% 的 WER 降低。
Self-supervised approaches for speech representation learning are challenged by three unique problems: (1) there are multiple sound units in each input utterance, (2) there is no lexicon of input sound units during the pre-training phase, and (3) sound units have variable lengths with no explicit segmentation. To deal with these three problems, we propose the Hidden-Unit BERT (HuBERT) approach for self-supervised speech representation learning, which utilizes an offline clustering step to provide aligned target labels for a BERT-like prediction loss. A key ingredient of our approach is applying the prediction loss over the masked regions only, which forces the model to learn a combined acoustic and language model over the continuous inputs. HuBERT relies primarily on the consistency of the unsupervised clustering step rather than the intrinsic quality of the assigned cluster labels. Starting with a simple k-means teacher of 100 clusters, and using two iterations of clustering, the HuBERT model either matches or improves upon the state-of-the-art wav2vec 2.0 performance on the Librispeech (960h) and Libri-light (60,000h) benchmarks with 10min, 1h, 10h, 100h, and 960h fine-tuning subsets. Using a 1B parameter model, HuBERT shows up to 19% and 13% relative WER reduction on the more challenging dev-other and test-other evaluation subsets.
研究动机与目标
- 解决自监督语音表征学习中的挑战:多个重叠的声音单元、无预定义词典、单元长度可变。
- 开发一种在预训练阶段无需依赖语言学标注即可学习鲁棒表征的方法。
- 通过在连续语音特征上应用类似 BERT 的掩码预测目标,提升下游 ASR 任务的泛化能力与性能。
- 研究聚类质量、超参数以及集成方法对模型性能的影响。
提出的方法
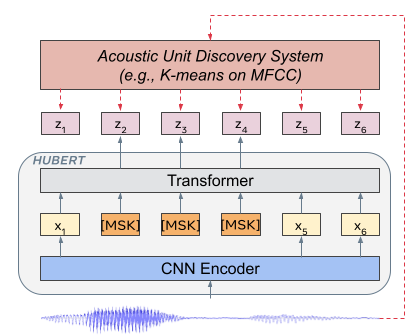
- 对 MFCC 或 HuBERT 特征进行离线 K-means 聚类,以生成用于掩码预测的离散目标单元。
- 模型使用类似 BERT 的 Transformer 架构,预测掩码语音帧的聚类分配,损失仅在掩码区域计算。
- 预测任务通过利用未掩码上下文重建掩码单元,迫使模型学习上下文相关的表征。
- 通过前序模型迭代的潜在表征,对聚类分配进行迭代优化,以提升目标质量。
- 采用多阶段训练流程,在迭代过程中逐步提升聚类目标的准确性,从而改善表征质量。
- 对有效批量大小和掩码概率进行调优,以优化泛化能力和收敛性。
实验结果
研究问题
- RQ1与预测全部或未掩码帧相比,仅预测掩码帧如何提升自监督语音表征学习?
- RQ2聚类质量对模型性能的影响如何,特别是在使用噪声大或质量差的聚类分配时?
- RQ3使用在不同特征类型或配置上训练的多个 k-means 模型的集成,如何影响表征质量?
- RQ4哪些超参数(如掩码概率和批量大小)对 HuBERT 性能影响最大?
- RQ5对聚类分配进行迭代优化是否能在不同规模的预训练数据上持续带来性能提升?
主要发现
- 在所有微调子集(10 分钟至 960 小时)上,HuBERT 在 Librispeech(960 小时)和 Libri-light(60,000 小时)上的表现达到或超过 SOTA 的 wav2vec 2.0。
- 使用 1B 参数模型,HuBERT 在更具挑战性的 Librispeech dev-other 集上实现了 19% 的相对 WER 降低,在 test-other 上实现了 13% 的降低。
- 仅预测掩码帧的性能显著优于预测全部或未掩码帧,尤其在聚类质量较低时更为明显。
- 训练时间更长(最多 800k 步)能持续提升性能,在 10 小时的 Libri-light 划分上达到最佳 WER 11.68%。
- 集成多个 k-means 模型(例如在拼接 MFCC 与乘积量化上训练)的性能优于单一聚类设置。
- 最优掩码概率为 8%,增加批量大小能显著提升模型泛化能力。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。