[论文解读] Impression Network for Video Object Detection
该论文提出Impression Network,一种新颖的视频目标检测特征级框架,通过迭代式印象特征聚合机制,利用稀疏关键帧中的高层特征来增强低质量帧。通过在长距离片段间实现最小计算开销的特征融合,该方法实现了20 fps的推理速度,并在ImageNet VID上超越了逐帧基线模型的精度,为高效、精准的视频特征增强提供了新范式。
Video object detection is more challenging compared to image object detection. Previous works proved that applying object detector frame by frame is not only slow but also inaccurate. Visual clues get weakened by defocus and motion blur, causing failure on corresponding frames. Multi-frame feature fusion methods proved effective in improving the accuracy, but they dramatically sacrifice the speed. Feature propagation based methods proved effective in improving the speed, but they sacrifice the accuracy. So is it possible to improve speed and performance simultaneously? Inspired by how human utilize impression to recognize objects from blurry frames, we propose Impression Network that embodies a natural and efficient feature aggregation mechanism. In our framework, an impression feature is established by iteratively absorbing sparsely extracted frame features. The impression feature is propagated all the way down the video, helping enhance features of low-quality frames. This impression mechanism makes it possible to perform long-range multi-frame feature fusion among sparse keyframes with minimal overhead. It significantly improves per-frame detection baseline on ImageNet VID while being 3 times faster (20 fps). We hope Impression Network can provide a new perspective on video feature enhancement. Code will be made available.
研究动机与目标
- 为解决视频目标检测中速度与精度之间的权衡,尤其是在图像退化(如对焦模糊和运动模糊)情况下的性能瓶颈。
- 实现在不增加高计算成本的前提下,高效实现长距离多帧特征融合。
- 通过累积时间上的视觉印象,模仿人类视觉感知机制,提升在低质量帧上的检测性能。
- 在保持实时推理速度的同时,超越逐帧检测基线模型的性能表现。
- 提供一种与任务无关的、基于特征层级的框架,用于提升下游检测任务的视频特征质量。
提出的方法
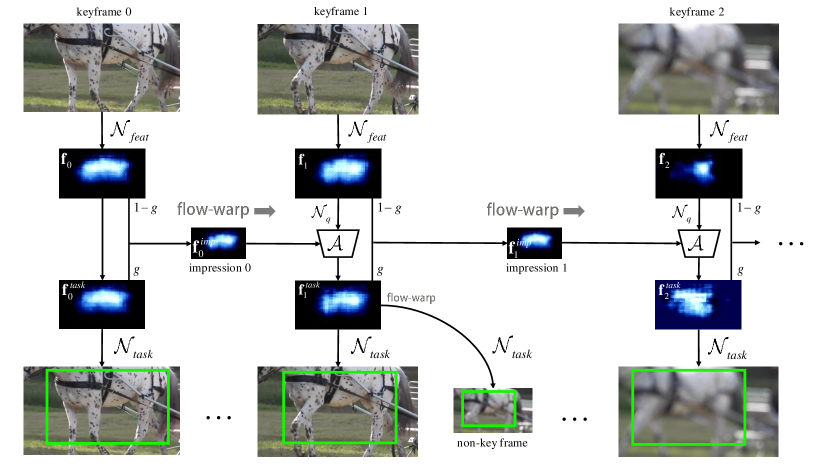
- 该框架将视频划分为固定长度的片段,并在每个片段中选取中心关键帧,使用ResNet-101等主干网络进行深度特征提取。
- 通过光流引导的特征传播机制,将在关键帧中提取的特征复用于非关键帧,以保持实时推理速度。
- 通过逐帧吸收新关键帧的特征,迭代更新印象特征,作为高层目标线索的累积记忆。
- 每个关键帧的任务特定特征是其自身特征与传播的印象特征的加权组合,从而实现在退化帧上的特征增强。
- 印象特征通过递归聚合规则进行更新:$ I_{t} = (1-g)I_{t-1} + g \cdot f_t $,其中 $ g $ 控制时间影响范围。
- 该方法仅需对每对片段进行一次光流估计,最小化空间对齐的计算开销,从而实现高效的长距离特征融合。
实验结果
研究问题
- RQ1通过利用时间上下文,是否能够实现一种特征级方法,在视频目标检测中同时达到高精度与高速度?
- RQ2如何在不牺牲推理速度的前提下,高效实现长距离特征融合?
- RQ3对过去特征的累积印象在多大程度上能提升在弱视觉线索的低质量帧上的检测性能?
- RQ4何种关键帧选择策略可使光流引导的特征传播误差最小化?
- RQ5与现有特征聚合与传播技术相比,该印象机制在精度与效率方面表现如何?
主要发现
- Impression Network 实现了20 fps的推理速度,比逐帧基线模型快三倍,同时显著提升了检测精度。
- 该方法优于最先进的基于聚合的方法(如FGFA),在ImageNet VID上达到75.5%的mAP,且仅需50ms的推理时间。
- 印象机制通过从前序关键帧传播高质量特征,有效提升了对焦模糊和模糊帧的检测性能,如图5与图1所示。
- 将聚合权重 $ g $ 设置为1.0可实现对全部时间上下文的利用,从而获得最高mAP,表明长距离特征融合显著增强了模型鲁棒性。
- 中心关键帧选择策略可最小化平均特征传播距离 $ \bar{d} $,降低光流误差,从而提升性能,该结论在表2中得到验证。
- 该方法在不同片段长度下均保持平滑的精度-速度权衡,在高速场景下优于逐帧基线模型与Deep Feature Flow。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。