[论文解读] Improving Code Generation by Training with Natural Language Feedback
本文提出 Language Feedback 的模仿学习(ILF),一种在训练阶段使用人类撰写的自然语言反馈与 refinements 来修正错误代码、提升 CodeGen 模型的通过率的方法,优于基线微调。
The potential for pre-trained large language models (LLMs) to use natural language feedback at inference time has been an exciting recent development. We build upon this observation by formalizing an algorithm for learning from natural language feedback at training time instead, which we call Imitation learning from Language Feedback (ILF). ILF requires only a small amount of human-written feedback during training and does not require the same feedback at test time, making it both user-friendly and sample-efficient. We further show that ILF can be seen as a form of minimizing the KL divergence to the ground truth distribution and demonstrate a proof-of-concept on a neural program synthesis task. We use ILF to improve a Codegen-Mono 6.1B model's pass@1 rate by 38% relative (and 10% absolute) on the Mostly Basic Python Problems (MBPP) benchmark, outperforming both fine-tuning on MBPP and fine-tuning on repaired programs written by humans. Overall, our results suggest that learning from human-written natural language feedback is both more effective and sample-efficient than training exclusively on demonstrations for improving an LLM's performance on code generation tasks.
研究动机与目标
- 在训练阶段利用人类撰写的反馈来提升代码生成,而非在测试时才使用,以激励改进。
- 将 ILF 正式化为对更高质量代码分布的真实分布最小化 KL 散度。
- 证明 ILF 在 MBPP 和人工修复数据上可以优于标准微调。
提出的方法
- 定义一个基于奖励的目标,其中 refinements 能提升单元测试通过率。
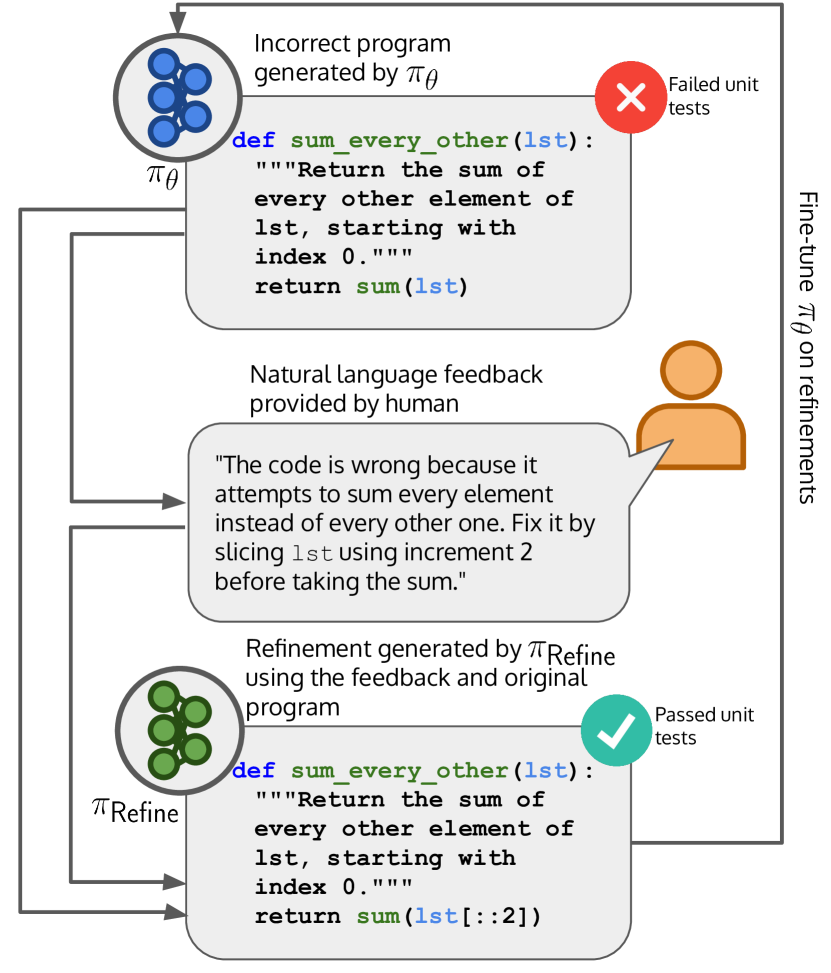
- 创建一个 refinment 模型 πRefine,训练使其在使用反馈 f 将不正确的代码 x0 转换为正确代码 x1。
- 构建一个提议分布 qt,使其在采样时优先考虑融入反馈的高质量 refinements。
- 在 πRefine 生成的 refinements 上对基础模型 θ 进行微调,以获得 θ*,实现迭代改进。
- 以 CodeGen-Mono 6.1B 作为基础模型,在 MBPP 上进行评估并计算 pass@k 指标。
- 将 ILF 与零-shot、MBPP gold 微调,以及 InstructGPT 生成的 refinements 等基线进行比较。
实验结果
研究问题
- RQ1用人类撰写的自然语言反馈进行训练,是否能在超越标准演示的情况下提升代码生成性能?
- RQ2ILF 与仅在 MBPP Gold 数据或人类撰写的 refinements 上训练相比如何?
- RQ3使用人类反馈与模型生成的反馈对最终通过率有何影响?
- RQ4refinement 的质量以及对多重错误的处理如何影响 ILF 的效果?
主要发现
| 方法 | 反馈来源 | 微调数据 | Pass@1 | Pass@10 |
|---|---|---|---|---|
| ILF | Humans | πRefine Refinements | 36% | 68% |
| Ablations | 1-shot InstructGPT | 1-shot InstructGPT Refinements | 19% | 55% |
| Ablations | 2-shot InstructGPT | 2-shot InstructGPT Refinements | 25% | 59% |
| Gold Standards | - | MBPP Gold | 22% | 63% |
| Gold Standards | - | Human Refinements | 33% | 68% |
| Baseline (zero-shot) | - | - | 26% | 59% |
- ILF 在 MBPP 上将 CodeGen-Mono 6.1B 的 pass@1 提升了相对 38%(绝对 10%)优于零-shot。
- ILF 在 MBPP Gold 程序上以及在对人类 refinements 进行微调的情况下,在 pass@1 上优于微调(分别为 14% 绝对、64% 相对;以及 3% 绝对、9% 相对)。
- 在 πRefine 生成的 refinements 上进行微调相较于单次反馈带来显著提升,并提高 refinements 的通过率(Pass@1:19% 对 0% 零-shot;Pass@10:47% 对 0%)。
- 人类撰写的反馈解决了更多错误且比 InstructGPT 的反馈更具信息性,从而带来更高的增益。
- 使用少量的人类撰写 refinements 进行训练也能带来具有竞争力的改进,且 ILF 在相对较少的反馈样本(总计 122 条)下也能发挥作用。
- ILF 可被视为一种实用、样本高效的监督学习形式,目标是最小化到更高质量代码分布的 KL 散度。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。