[论文解读] Improving Language Model Negotiation with Self-Play and In-Context Learning from AI Feedback
本文研究多个人工智能语言模型是否能通过自我对弈、来自评审模型的AI反馈以及上下文学习来自主改进谈判策略,结果显示部分模型在多轮迭代中持续改进,而其他模型则未能改进。
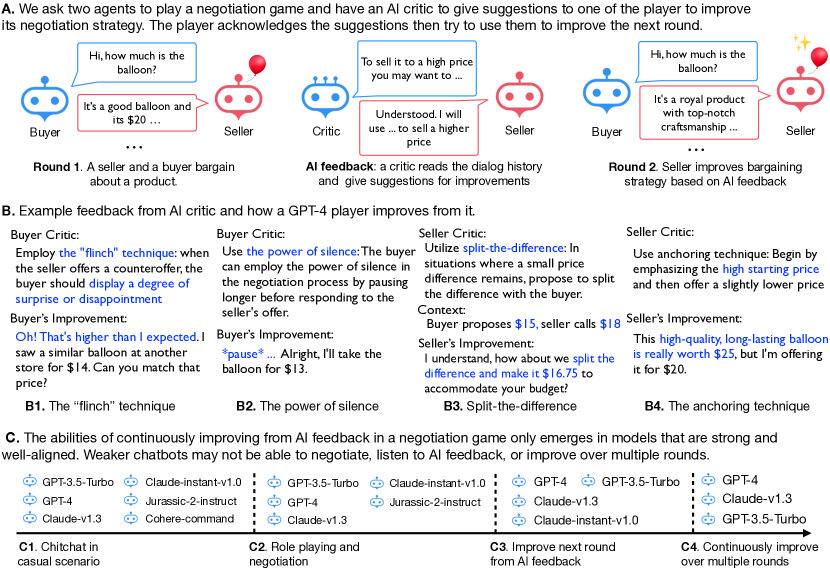
We study whether multiple large language models (LLMs) can autonomously improve each other in a negotiation game by playing, reflecting, and criticizing. We are interested in this question because if LLMs were able to improve each other, it would imply the possibility of creating strong AI agents with minimal human intervention. We ask two LLMs to negotiate with each other, playing the roles of a buyer and a seller, respectively. They aim to reach a deal with the buyer targeting a lower price and the seller a higher one. A third language model, playing the critic, provides feedback to a player to improve the player's negotiation strategies. We let the two agents play multiple rounds, using previous negotiation history and AI feedback as in-context demonstrations to improve the model's negotiation strategy iteratively. We use different LLMs (GPT and Claude) for different roles and use the deal price as the evaluation metric. Our experiments reveal multiple intriguing findings: (1) Only a subset of the language models we consider can self-play and improve the deal price from AI feedback, weaker models either do not understand the game's rules or cannot incorporate AI feedback for further improvement. (2) Models' abilities to learn from the feedback differ when playing different roles. For example, it is harder for Claude-instant to improve as the buyer than as the seller. (3) When unrolling the game to multiple rounds, stronger agents can consistently improve their performance by meaningfully using previous experiences and iterative AI feedback, yet have a higher risk of breaking the deal. We hope our work provides insightful initial explorations of having models autonomously improve each other with game playing and AI feedback.
研究动机与目标
- 通过游戏对弈和AI反馈在尽量少的人类干预下推动语言模型的自主改进的可能性。
- 研究一个买家-卖家谈判情境,其中两端LLM进行定价谈判,第三个LLM提供反馈以提高被评玩家的表现。
- 评估不同LLMs对AI反馈的反应,以及它们是否能够在多轮中改进。
- 考察在迭代轮次中实现更高的交易价格与达成交易的概率之间的权衡。
提出的方法
- 两名LLM进行买家-卖家讨价还价博弈,设定价格目标(买家目标价格低,卖家目标价格高)。
- 第三个LLM充当评审,用自然语言反馈在每一轮后改进目标玩家。
- 通过将先前的谈判历史和AI反馈作为示范用于后续轮次的上下文学习(ICL-AIF)。
- 测试多种引擎组合(GPT和Claude家族),以gpt-3.5-turbo作为基线对手;交易价格作为评估指标。
- 一个 moderator 模型对游戏状态进行分类(进行中、达成、未达成)以管理轮次。
- 实验包括单轮基线、多轮改进,以及最多五轮的持续改进。
实验结果
研究问题
- RQ1是否能通过自对弈和AI反馈让多种LLM在谈判游戏中相互自主改进?
- RQ2哪些模型能够理解议价规则并对AI反馈做出反应以在多轮中改进?
- RQ3买家角色是否比卖家角色在改进方面更具挑战性?不同模型的差异如何?
- RQ4在迭代轮次中实现更高的交易价格与达成交易的可能性之间的权衡是什么?
主要发现
| GPT-3.5-Turbo | Claude-instant-v1.0 | Claude-v1.3 | |
|---|---|---|---|
| Before feedback | 16.26 | 14.74 | 15.40 |
| Random sampled human feedback | 16.83 (+0.57) | 16.33 (+1.59) | 16.89 (+1.58) |
| AI feedback | 17.03 (+0.77) | 15.98 (+1.24) | 16.98 (+1.58) |
- 只有一部分被测试的模型(如 gpt-3.5-turbo、gpt-4、claude-v1.3)能够从迭代的AI反馈中在多轮中持续改进。
- 买家角色对若干模型而言通常比卖家角色更难改进;一些模型仍能作为买家改进(如GPT-4、claude-v1.3),而其他模型则不能。
- 更强的代理通过利用先前的经验和AI反馈可以在多轮中改进,但更高的价格会增加未达成交易的风险。
- AI反馈可以带来与人类反馈相近的改进,并且在引导谈判策略方面更具可扩展性。
- 在多轮设置中,增大冗长性伴随学习,但策略质量(不仅是长度)推动更好的交易结果。
- 研究强调在代理从AI反馈学习时交易质量与交易可靠性之间的权衡。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。