[论文解读] Improving Multimodal Datasets with Image Captioning
本论文表明,向网络抓取的图像-文本数据添加由图像字幕模型生成的合成字幕,可以改善 CLIP 的训练,在小到中等规模下优于强基线,以原始数据筛选为对比,并提供有关字幕质量、多样性和规模效应的见解。
Massive web datasets play a key role in the success of large vision-language models like CLIP and Flamingo. However, the raw web data is noisy, and existing filtering methods to reduce noise often come at the expense of data diversity. Our work focuses on caption quality as one major source of noise, and studies how generated captions can increase the utility of web-scraped datapoints with nondescript text. Through exploring different mixing strategies for raw and generated captions, we outperform the best filtering method proposed by the DataComp benchmark by 2% on ImageNet and 4% on average across 38 tasks, given a candidate pool of 128M image-text pairs. Our best approach is also 2x better at Flickr and MS-COCO retrieval. We then analyze what makes synthetic captions an effective source of text supervision. In experimenting with different image captioning models, we also demonstrate that the performance of a model on standard image captioning benchmarks (e.g., NoCaps CIDEr) is not a reliable indicator of the utility of the captions it generates for multimodal training. Finally, our experiments with using generated captions at DataComp's large scale (1.28B image-text pairs) offer insights into the limitations of synthetic text, as well as the importance of image curation with increasing training data quantity. The synthetic captions used in our experiments are now available on HuggingFace.
研究动机与目标
- 通过聚焦字幕质量来改善嘈杂的网络规模图像-文本数据集的动机。
- 评估 BLIP2 等模型生成的合成字幕对多模态预训练的影响。
- 比较原始与合成字幕混合策略与传统筛选之间的差异。
- 分析字幕的质量因素,如噪声、多样性,以及图像-文本对齐,以解释性能提升。
提出的方法
- 使用字幕模型(BLIP、BLIP2、OpenCLIP-CoCa)对网络抓取的图像-文本对生成合成字幕,采用 top-K 采样。
- 在小、 中、 大候选池(12.8M、128M、1.28B)下,将包含合成字幕的图像-文本对用于训练 CLIP。
- 在零-shot ImageNet、38 任务平均准确率,以及在 Flickr30K 和 MS-COCO 的检索任务上进行评估。
- 比较不同字幕模型在 MS-COCO 上是否微调与否对下游 CLIP 性能的影响。
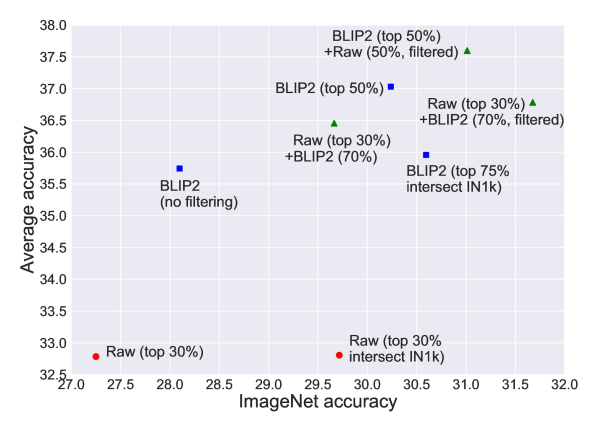
- 尝试数据混合策略,包括不筛选、CLIP-score 筛选,以及在余弦相似度阈值下混合原始与合成字幕。

实验结果
研究问题
- RQ1相比仅对原始网络数据进行筛选,合成字幕是否能改善 CLIP 训练?
- RQ2不同字幕模型及其训练(微调与否)如何影响多模态训练的有效性?
- RQ3哪些原始与合成字幕的混合策略能最大化性能,且这随数据规模如何变化?
- RQ4字幕的哪些特性(噪声、多样性、对齐)驱动下游任务的改进?
- RQ5合成字幕的好处在从小规模到超大规模数据池的扩展中如何体现?
主要发现
| 方法 | 平均检索(MS-COCO 与 Flickr) |
|---|---|
| 原始(无筛选) | 13.2 |
| 原始(前30% 与 IN1k 相交) | 18.2 |
| 原始(前30%) | 19.7 |
| 原始(前30%)+ BLIP2(70%,已筛选) | 38.0 |
| BLIP2(前75% 与 IN1k 相交) | 38.9 |
| BLIP2(前50%) | 40.1 |
| 原始(前30%)+ BLIP2(70%) | 40.5 |
| BLIP2(无筛选) | 41.7 |
- 未在字幕目标上进行微调的字幕模型往往在 ImageNet 与检索方面获得更好的整体 CLIP 性能,因为文本多样性更高。
- 合成字幕通常显示出比原始字幕更高的图像-文本对齐度(噪声更低),而原始字幕提供更高的多样性;在相似度阈值下将两者结合可获得更好的结果。
- 在中等规模(128M)下,以余弦相似度阈值混合原始和合成字幕,较最佳原始数据基线在 ImageNet 上提升约 2%,在任务的平均 38 项上提升约 4%。
- BLIP2 生成的字幕在 Flickr 与 MS-COCO 检索方面显著提升(超过原始字幕的两倍以上)。
- 在大规模(4–1.28B)时,如果不解决图像内容筛选和文本多样性问题,ImageNet 的收益将减弱,而合成字幕在检索方面的收益在各规模仍然存在。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。