[论文解读] Improving the Model Consistency of Decentralized Federated Learning
本文提出 DFedSAM 与 DFedSAM-MGS,将 Sharpness Aware Minimization 与多轮 gossip 步骤整合到去中心化联邦学习中,以降低本地模型不一致性、给出理论收敛保证,并在与集中式 FL 的对比中呈现具有竞争力的经验结果。
To mitigate the privacy leakages and communication burdens of Federated Learning (FL), decentralized FL (DFL) discards the central server and each client only communicates with its neighbors in a decentralized communication network. However, existing DFL suffers from high inconsistency among local clients, which results in severe distribution shift and inferior performance compared with centralized FL (CFL), especially on heterogeneous data or sparse communication topology. To alleviate this issue, we propose two DFL algorithms named DFedSAM and DFedSAM-MGS to improve the performance of DFL. Specifically, DFedSAM leverages gradient perturbation to generate local flat models via Sharpness Aware Minimization (SAM), which searches for models with uniformly low loss values. DFedSAM-MGS further boosts DFedSAM by adopting Multiple Gossip Steps (MGS) for better model consistency, which accelerates the aggregation of local flat models and better balances communication complexity and generalization. Theoretically, we present improved convergence rates $\small \mathcal{O}\big(\frac{1}{\sqrt{KT}}+\frac{1}{T}+\frac{1}{K^{1/2}T^{3/2}(1-λ)^2}\big)$ and $\small \mathcal{O}\big(\frac{1}{\sqrt{KT}}+\frac{1}{T}+\frac{λ^Q+1}{K^{1/2}T^{3/2}(1-λ^Q)^2}\big)$ in non-convex setting for DFedSAM and DFedSAM-MGS, respectively, where $1-λ$ is the spectral gap of gossip matrix and $Q$ is the number of MGS. Empirically, our methods can achieve competitive performance compared with CFL methods and outperform existing DFL methods.
研究动机与目标
- 激发并解决去中心化联邦学习(DFL)中本地模型之间高度不一致的问题。
- 提出 DFedSAM,通过 Sharpness Aware Minimization (SAM) 生成本地更平坦的模型。
- 在 DFedSAM-MGS 中通过引入多轮 gossip 步骤(MGS)来提升共识并在通信与泛化之间取得平衡。
- 提供非凸情形下的收敛性保证,覆盖拓扑结构(谱隙)、数据异质性、SAM扰动和 MGS 的影响。
- 通过实验证明所提方法在 CIFAR-10/100 上的表现与 CFL 竞争并且优于现有 DFL 基线。
提出的方法
- 在连通图上定义仅与邻居通信的 DFL 目标。
- 应用基于 SAM 的本地更新:y^{t,k+1}(i)=y^{t,k}(i) - η ∇F_i(y^{t,k}(i) + δ(y^{t,k}); ξ) 其中 δ(y)=ρ g/||g||_2。
- 在通信前进行 K 次本地内部迭代以获得 z^{t}(i),然后聚合:x^{t+1}(i) = ∑_{l∈N(i)} w_{i,l} z^{t}(l)。
- 对于 DFedSAM-MGS,在每轮引入 Q 次 gossip 步骤,更新 x^{t,q+1}(i)=∑_{l∈N(i)} w_{i,l} z^{t,q}(l) 且 z^{t,q+1}(i)=x^{t,q+1}(i) 其中 q=0,...,Q-1。
- 在非凸设定下给出理论收敛界:O(1/√(KT) + 1/T + 取决于 (1−λ) 与 Q 的项)。
- 通过在 CIFAR-10/100 的 IID 与非 IID 划分上进行实验,与基线(FedAvg、FedSAM、D-PSGD、DFedAvg、DisPFL)进行比较。
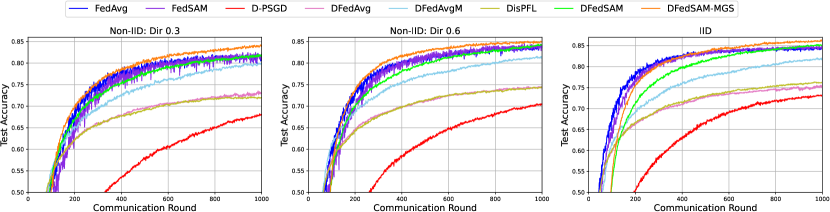
实验结果
研究问题
- RQ1SAM 是否能够降低去中心化联邦学习中的本地模型过拟合并提升泛化能力?
- RQ2增加 gossip 步骤(MGS)是否能够提升模型共识并缩小与 CFL 的差距,在不同拓扑结构下?
- RQ3在随机非凸去中心化设置中,DFedSAM 与 DFedSAM-MGS 的收敛性保证是什么?
- RQ4数据异质性与拓扑结构(谱隙)如何影响性能,所提方法如何缓解这些影响?
- RQ5在标准数据集上, DFedSAM 与 DFedSAM-MGS 的性能是否具有竞争力或优于 CFL 与现有 DFL 基线?
主要发现
| Algorithm | Ring | Grid | Exp | Full |
|---|---|---|---|---|
| D-PSGD | 68.96 | 74.36 | 74.90 | 75.35 |
| DFedAvg | 69.95 | 80.17 | 83.13 | 83.48 |
| DFedAvgM | 72.55 | 85.24 | 86.94 | 87.50 |
| DFedSAM | 73.19 | 85.28 | 87.44 | 88.05 |
| DFedSAM-MGS | 80.55 | 87.39 | 88.06 | 88.20 |
- DFedSAM,尤其是 DFedSAM-MGS,在 CIFAR-10/100 的 IID 与非 IID 设置下实现了与集中式 FedSAM 的竞争性能。
- DFedSAM-MGS 显著提升了拓扑鲁棒性,相较于其他 DFL 基线在环型、网格、指数型和全连接网络中均有性能提升。
- 这些方法降低了泛化误差并产生更加平坦的损失景观,表明客户端之间的模型一致性得到改善。
- 理论收敛速率显示出对拓扑(谱隙)、MGS 步数 Q、扰动半径 ρ 的依赖性提升,与经验结果一致。
- 实证结果表明更大的 Q(多次 gossip 步骤)提高了共识并缓解了拓扑引起的降级,DFedSAM-MGS 往往优于 DFedSAM 和其他基线。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。