[论文解读] In-Context Learning for Extreme Multi-Label Classification
论文提出 Infer--Retrieve--Rank,这是一个模块化的 in-context 学习程序,结合一个冻结检索器和两个 in-context LM 模块,在不微调的情况下处理极端多标签分类,并在若干基准数据集上取得了最先进的结果。优化使用 DSPy 通过只有数十个有标签的示例对提示进行引导。
Multi-label classification problems with thousands of classes are hard to solve with in-context learning alone, as language models (LMs) might lack prior knowledge about the precise classes or how to assign them, and it is generally infeasible to demonstrate every class in a prompt. We propose a general program, $ exttt{Infer--Retrieve--Rank}$, that defines multi-step interactions between LMs and retrievers to efficiently tackle such problems. We implement this program using the $ exttt{DSPy}$ programming model, which specifies in-context systems in a declarative manner, and use $ exttt{DSPy}$ optimizers to tune it towards specific datasets by bootstrapping only tens of few-shot examples. Our primary extreme classification program, optimized separately for each task, attains state-of-the-art results across three benchmarks (HOUSE, TECH, TECHWOLF). We apply the same program to a benchmark with vastly different characteristics and attain competitive performance as well (BioDEX). Unlike prior work, our proposed solution requires no finetuning, is easily applicable to new tasks, alleviates prompt engineering, and requires only tens of labeled examples. Our code is public at https://github.com/KarelDO/xmc.dspy.
研究动机与目标
- 仅使用上下文学习时,面对成千上万个类别的极端多标签分类(XMC)挑战。
- 提出一个模块化流程(Infer--Retrieve--Rank),利用冻结组件和最小监督以达到更强的性能。
- 通过 DSPy 编程模型自动化提示引导和优化,以在不进行微调的情况下适应多样的数据集。
- 在多个 XMC 基准测试(HOUSE、TECH、TECHWOLF、BioDEX)中展示有效性,并展示成本高效的部署。
提出的方法
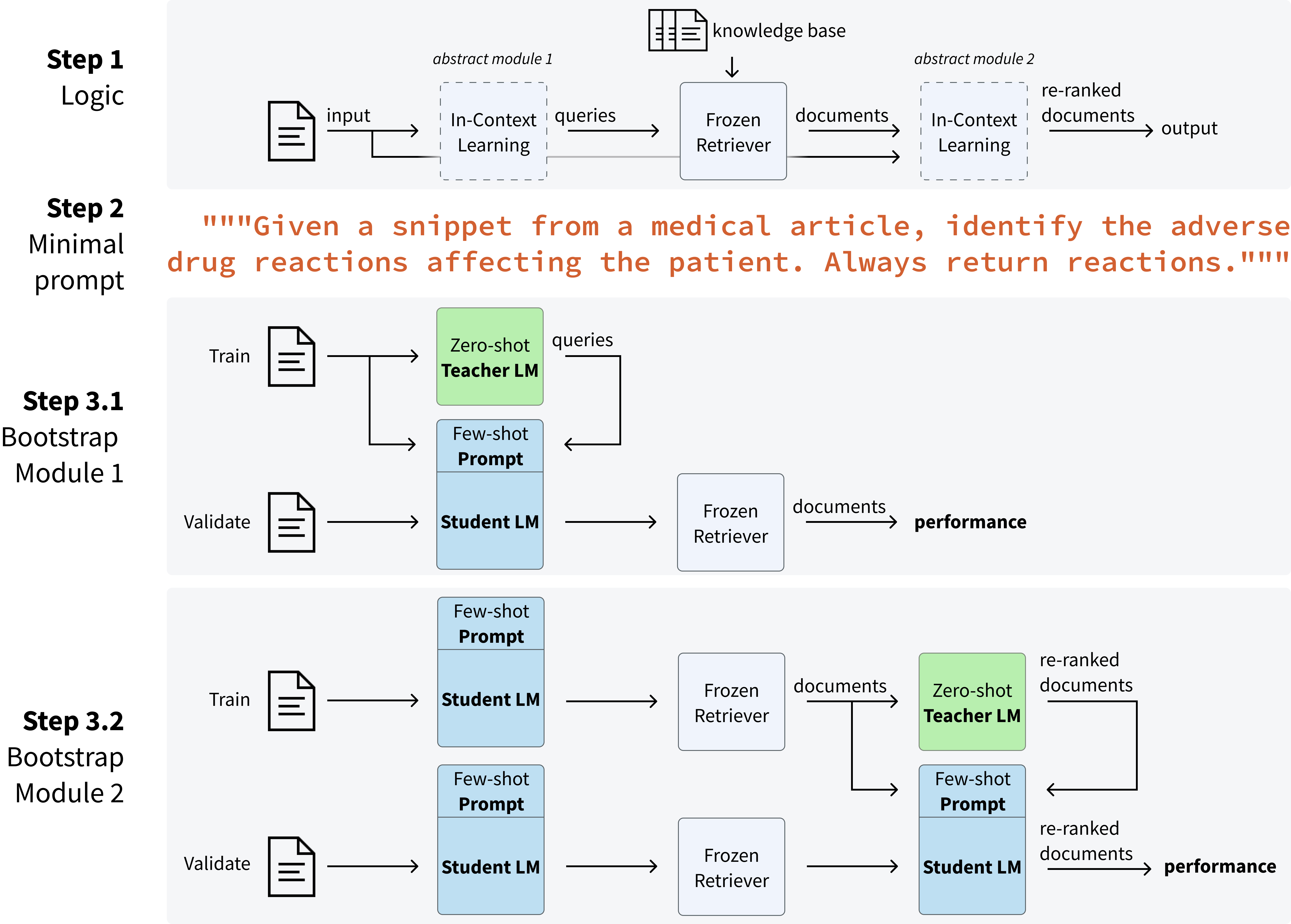
- 引入 Infer--Retrieve--Rank (IReRa),一个三步程序:Infer(LM 基于输入预测相关的标签查询),Retrieve(一个冻结检索器按查询相似度对标签进行排序),Rank(LM 重新对检索得到的标签进行排序)。
- 使用 DSPy 框架实现该程序,以声明式方式指定模块并针对每个任务用引导的少样本提示进行优化。
- 使用一个零-shot 的教师 LM 为两个 LM 组件引导少样本提示,优化依赖于大约 50 个带标签的验证样本以及每个任务大约 20 次教师调用 + 1,500 次学生 LM 调用。
- 用 Llama-2-7b-chat(学生)和 GPT-3.5(教师)实例化 Infer;用 GPT-4 实例化 Rank;用冻结的 all-mpnet-base-v2/BioLORD 风格的检索器实现 Retrieve。
- 为每个数据集提供种子提示,定义每个模块(Infer/Rank)的上下文行为以及最小的零-shot 提示,由 DSPy 处理引导和标签的选择。
- 在四个数据集上评估 RP@5 和 RP@10 指标,并与之前的基线和微调系统进行比较。
实验结果
研究问题
- RQ1一个模块化的 in-context 学习流程在不进行微调的情况下能否达到具竞争力或最先进的 XMC 性能?
- RQ2为每个任务引导出一个高性能的 IReRa 程序需要多少带标签数据和多少次 LM 调用?
- RQ3每个模块(Infer、Retrieve、Rank)及其优化对 XMC 性能的影响是什么?
- RQ4该方法如何在具有不同特征的任务之间泛化(生物医学 vs. ESCO 岗位技能)?
主要发现
| 数据集 | RP@5 | RP@10 |
|---|---|---|
| HOUSE | 56.50 | 65.76 |
| TECH | 59.61 | 70.23 |
| TECHWOLF | 57.04 | 65.17 |
| BioDEX | 24.73 | 27.67 |
- IReRa 在 HOUSE、TECH 和 TECHWOLF 数据集上在无需微调的情况下实现了最先进的 RP@5 与 RP@10,且大约有 50 个带标签的验证样本。
- 在 BioDEX 上,IReRa 显示出显著的推进,但并不严格优于最佳微调系统;增加 Rank 模块或进一步优化 Infer 可提升结果。
- 最佳程序 Infer--Retrieve--Rank 使用一个冻结的检索器和两个 LM 模块,引导成本约为每个任务 20 次教师调用和 1,500 次学生调用,以及每个新输入大约每个模块一次 LM 调用。
- 优化步骤(Infer、Retrieve、Rank)各自对性能提升有贡献;即使是更简单的 Infer--Retrieve 设置,在只有一个 LM 和一个冻结检索器的情况下也能实现具竞争力的结果。
- 与微调系统相比,IReRa 提供了较低的数据需求并避免了大量提示工程,同时通过最小种子提示和 DSPy 驱动的优化,仍然能够适应新数据集。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。