[论文解读] InstanSeg: an embedding-based instance segmentation algorithm optimized for accurate, efficient and portable cell segmentation
InstanSeg 是一个基于嵌入的实例分割管道,在细胞/核分割方面实现更高的准确性并且推理速度显著更快,具 TorchScript 序列化和 QuPath 扩展,便于集成。
Cell and nucleus segmentation are fundamental tasks for quantitative bioimage analysis. Despite progress in recent years, biologists and other domain experts still require novel algorithms to handle increasingly large and complex real-world datasets. These algorithms must not only achieve state-of-the-art accuracy, but also be optimized for efficiency, portability and user-friendliness. Here, we introduce InstanSeg: a novel embedding-based instance segmentation pipeline designed to identify cells and nuclei in microscopy images. Using six public cell segmentation datasets, we demonstrate that InstanSeg can significantly improve accuracy when compared to the most widely used alternative methods, while reducing the processing time by at least 60%. Furthermore, InstanSeg is designed to be fully serializable as TorchScript and supports GPU acceleration on a range of hardware. We provide an open-source implementation of InstanSeg in Python, in addition to a user-friendly, interactive QuPath extension for inference written in Java. Our code and pre-trained models are available at https://github.com/instanseg/instanseg .
研究动机与目标
- 提高在多样化显微镜数据集上的核/细胞实例分割准确性。
- 提高大规模和真实世界生物医学数据集上的推理速度和效率。
- 通过 TorchScript 序列化和跨语言集成(QuPath 扩展)提升可移植性和易用性。
- 提供一个端到端、GPU 加速、非专有的管道,适合集成到现有生物图像工作流。
提出的方法
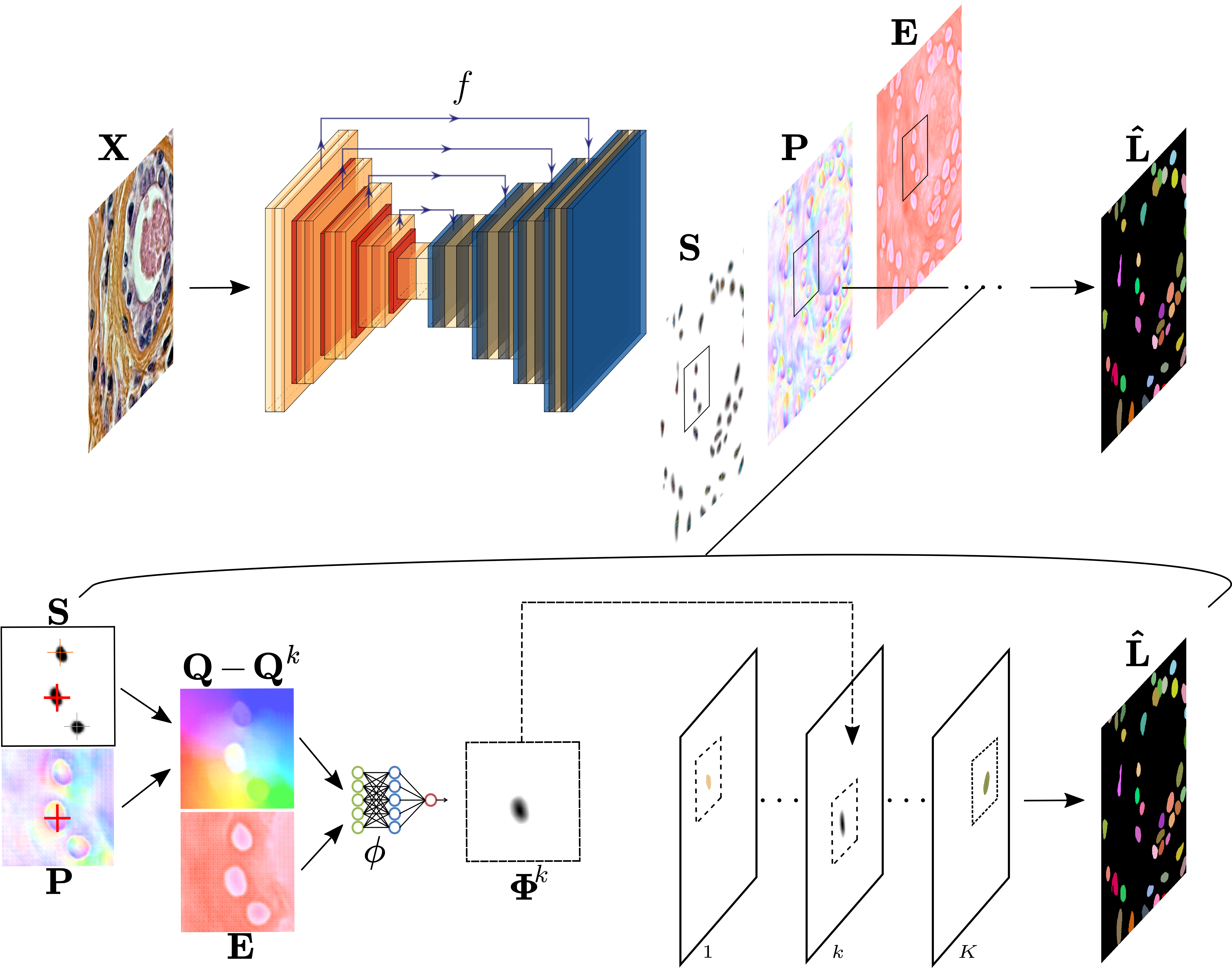
- 基于嵌入的分割,采用改进的 UNet 主干。
- 基于种子的像素分配:预测种子图、位置嵌入和条件嵌入。
- 通过使用像素偏移和嵌入的神经网络头 Phi 实现实例概率映射。
- 使用组合损失进行训练:种子损失 Ls(到实例边界的距离)和实例损失 Li(带单对多标签的 Lovasz hinge)。
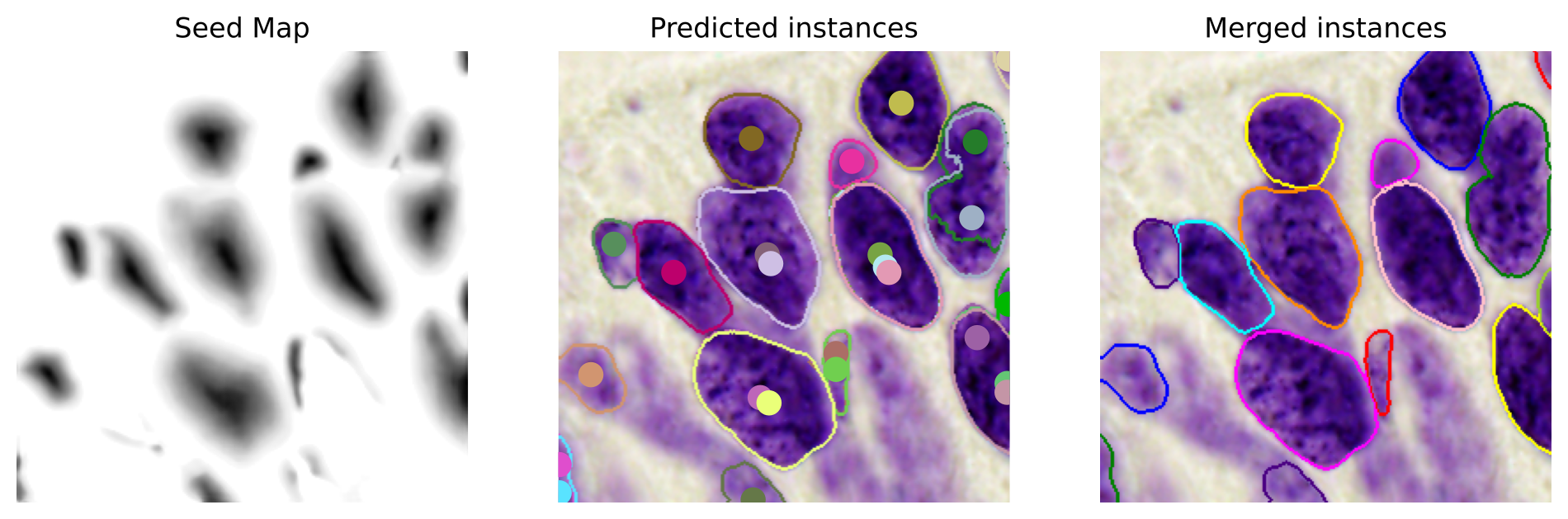
- 推理在局部极大处采样种子,计算偏移量 Qij−Qk,并通过基于 IoU 的并集合并重叠的实例预测。
实验结果
研究问题
- RQ1基于嵌入的方法结合学习的种子传播,是否能够在多样化核数据集上达到最先进的准确性?
- RQ2以种子为中心的神经聚类方法是否在保持高效与可移植性的同时改善接触/重叠核的分割?
- RQ3InstanSeg 在标准硬件上的推理速度和内存表现如何,包括在受限 GPU 的环境中?
- RQ4方法是否能够序列化并集成到非 Python 工具(TorchScript)以及 GUI 工作流(QuPath 扩展)中,而不牺牲性能?
- RQ5使用更高维度的位置/条件嵌入对分割准确性的影响是什么?
主要发现
| Dataset | StarDist F1_mu | StarDist F1_0.5 | HoVer-Net F1_mu | HoVer-Net F1_0.5 | CellPose F1_mu | CellPose F1_0.5 | EmbedSeg F1_mu | EmbedSeg F1_0.5 | InstanSeg F1_mu | InstanSeg F1_0.5 | InstanSeg F1_mu (TTA) | InstanSeg F1_0.5 (TTA) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TNBC 2018 | 0.645 | 0.896 | 0.546 | 0.768 | 0.627 | 0.835 | 0.641 | 0.870 | 0.699 | 0.898 | 0.704 | 0.899 |
| NuInsSeg | 0.494 | 0.799 | 0.374 | 0.635 | 0.497 | 0.788 | 0.492 | 0.761 | 0.511 | 0.787 | 0.527 | 0.805 |
| MoNuSeg | 0.543 | 0.846 | 0.438 | 0.707 | 0.553 | 0.850 | - | - | 0.575 | 0.861 | 0.566 | 0.860 |
| IHC TMA | 0.470 | 0.798 | 0.304 | 0.559 | 0.545 | 0.811 | - | - | 0.560 | 0.836 | 0.573 | 0.834 |
| CoNSeP | 0.418 | 0.690 | 0.312 | 0.538 | 0.389 | 0.626 | - | - | 0.483 | 0.706 | 0.491 | 0.709 |
| LyNSeC | 0.701 | 0.920 | 0.659 | 0.886 | 0.701 | 0.911 | - | - | 0.724 | 0.923 | 0.725 | 0.922 |
- InstanSeg 在六个公开核数据集上达到最先进或具竞争力的准确性,且通常优于基线。
- 推理显著快于基线,InstanSeg 对于包含 36,073 个实例的 199 张图像,在笔记本 GPU 上总时长约 9.4 秒,且后处理时间明显低于 EmbedSeg。
- TorchScript 序列化模型和 QuPath 扩展实现可移植、跨语言使用,包括在 Apple 与 NVIDIA 硬件上的 GPU 加速。
- 消融显示,添加高维位置嵌入(De > 2)和包含条件嵌入(De > 0)可提升准确性;移除这些组件会降低性能。
- 在各数据集上,InstanSeg 在 F1 指标上始终优于 StarDist、HoVer-Net、CellPose 和 EmbedSeg,TTA 在大多数情况下带来额外提升。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。