[论文解读] INSTRUCTEVAL: Towards Holistic Evaluation of Instruction-Tuned Large Language Models
InstructEval 提供一个全面的基准套件,用于评估指令微调的大语言模型在解决问题、写作和对人类价值观的对齐方面的表现,分析预训练、指令数据和训练方法的影响。
Instruction-tuned large language models have revolutionized natural language processing and have shown great potential in applications such as conversational agents. These models, such as GPT-4, can not only master language but also solve complex tasks in areas like mathematics, coding, medicine, and law. Despite their impressive capabilities, there is still a lack of comprehensive understanding regarding their full potential, primarily due to the black-box nature of many models and the absence of holistic evaluation studies. To address these challenges, we present INSTRUCTEVAL, a more comprehensive evaluation suite designed specifically for instruction-tuned large language models. Unlike previous works, our evaluation involves a rigorous assessment of models based on problem-solving, writing ability, and alignment to human values. We take a holistic approach to analyze various factors affecting model performance, including the pretraining foundation, instruction-tuning data, and training methods. Our findings reveal that the quality of instruction data is the most crucial factor in scaling model performance. While open-source models demonstrate impressive writing abilities, there is substantial room for improvement in problem-solving and alignment. We are encouraged by the rapid development of models by the open-source community, but we also highlight the need for rigorous evaluation to support claims made about these models. Through INSTRUCTEVAL, we aim to foster a deeper understanding of instruction-tuned models and advancements in their capabilities. INSTRUCTEVAL is publicly available at https://github.com/declare-lab/instruct-eval.
研究动机与目标
- 评估指令微调的LLMs超越传统基准的整体能力。
- 分析预训练基础、指令数据和训练方法如何影响性能。
- 确定哪些因素最有效地提升模型能力的可扩展性。
- 提供对全面评估框架和排行榜的开源访问。
提出的方法
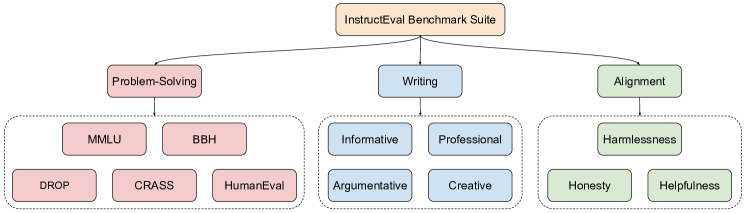
- 定义一个覆盖问题解决、写作和对人类价值观对齐的整体评估套件。
- 使用多种客观和主观评估方法,包括自动和人机参与评估。
- 使用标准化基准(MMLU、BBH、DROP、CRASS、HumanEval、HHH,以及一个影响写作数据集)比较超过60个开源指令LLM。
- 分析基础模型规模、指令数据质量和训练方法(监督学习与 RLHF、参数高效微调)的影响。
- 研究少量示例与零-shot 表现以及跨任务的上下文学习效应。
实验结果
研究问题
- RQ1指令微调因素(基础模型、数据质量和训练方法)如何影响问题解决、写作和对齐性能?
- RQ2在提升性能的可扩展性方面,指令数据相对于预训练基础的重要性如何?
- RQ3开源指令LLM在写作和对齐方面是否能达到甚至接近闭源模型?在问题解决方面它们落在哪里?
- RQ4少量示例是否在所有任务和模型中都能持续提高性能?
主要发现
- 指令数据质量是提升性能的最关键因素。
- 开源指令LLMs在写作方面表现出色,但在问题解决和对齐方面存在显著差距。
- 通过合成指令模仿闭源模型收益有限,且可能传播偏见/噪声。
- 训练方法(例如 RLHF)有帮助,但总体影响通常小于指令数据;参数高效微调随模型规模扩展性良好。
- 少量示例在所有任务上并非普遍受益;收益取决于任务,有时为负。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。