[论文解读] Instruction-Following Evaluation for Large Language Models
IFEval 是一个自动基准测试,用于评估 LLM 在可验证指令上的表现,减少对人工或基于模型的判断的依赖。
One core capability of Large Language Models (LLMs) is to follow natural language instructions. However, the evaluation of such abilities is not standardized: Human evaluations are expensive, slow, and not objectively reproducible, while LLM-based auto-evaluation is potentially biased or limited by the ability of the evaluator LLM. To overcome these issues, we introduce Instruction-Following Eval (IFEval) for large language models. IFEval is a straightforward and easy-to-reproduce evaluation benchmark. It focuses on a set of "verifiable instructions" such as "write in more than 400 words" and "mention the keyword of AI at least 3 times". We identified 25 types of those verifiable instructions and constructed around 500 prompts, with each prompt containing one or more verifiable instructions. We show evaluation results of two widely available LLMs on the market. Our code and data can be found at https://github.com/google-research/google-research/tree/master/instruction_following_eval
研究动机与目标
- 推动对大型语言模型在安全性和可靠性方面的指令遵循进行标准化评估的需求。
- 引入可验证的指令,以实现客观、自动化的评估。
- 构建包含可验证指令的提示数据集,并给出在流行模型上的基线结果。
提出的方法
- 定义可以在回答中客观验证的可验证指令。
- 创建大约 500 个提示,每个提示包含一个或多个可验证指令,涵盖 25 种指令类型。
- 提出严格和宽松的指令遵循准确性指标,以应对验证边界情形。
- 在两个模型(GPT-4 和 PaLM 2 S)上进行提示级和指令级评估。
- 描述提示综合过程,包括基础提示、少量示例筛选和改写步骤。

实验结果
研究问题
- RQ1是否可以使用可验证指令以客观方式衡量指令遵循的准确性?
- RQ2不同指令类别如何影响模型对指令的遵守程度?
- RQ3在可验证指令上,广泛可用的 LLM 的基线指令遵循表现如何?
- RQ4严格和宽松的验证标准在实际中如何比较?
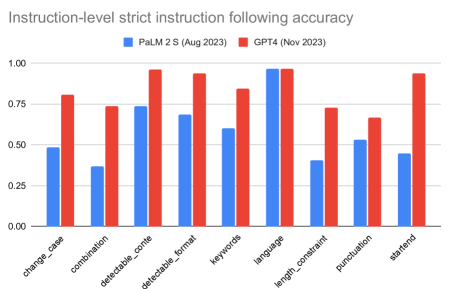
主要发现
| 模型 | 提示级严格准确度 (%) | 指令级严格准确度 (%) | 提示级宽松准确度 (%) | 指令级宽松准确度 (%) |
|---|---|---|---|---|
| GPT-4 | 76.89 | 83.57 | 79.30 | 85.37 |
| PaLM 2 S | 43.07 | 55.76 | 46.95 | 59.11 |
- IFEval 实现了对广泛可验证提示集的指令遵循的自动化验证。
- 在严格和宽松指标上,GPT-4 的准确性高于 PaLM 2 S。
- 由于边缘情况和验证挑战,严格准确度低于宽松准确度。
- 在详细的类别分析中,指令遵循在不同类别中存在差异。
- 评估框架具有可重复性,作者公开提供代码和提示。
- 这两种评估指标(严格和宽松)有助于在验证中平衡假阳性和假阴性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。