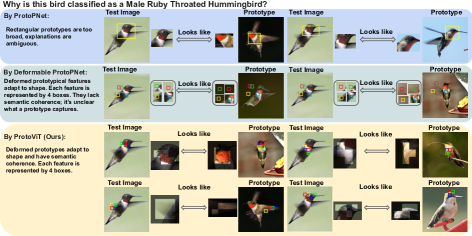
[论文解读] Interpretable Image Classification with Adaptive Prototype-based Vision Transformers
ProtoViT 将 Vision Transformer 主干与自适应、可变形原型结合起来,通过基于案例的推理实现可解释的图像分类,在原型模型中达到最先进的准确率,同时确保连贯、真实的解释。
We present ProtoViT, a method for interpretable image classification combining deep learning and case-based reasoning. This method classifies an image by comparing it to a set of learned prototypes, providing explanations of the form ``this looks like that.'' In our model, a prototype consists of extit{parts}, which can deform over irregular geometries to create a better comparison between images. Unlike existing models that rely on Convolutional Neural Network (CNN) backbones and spatially rigid prototypes, our model integrates Vision Transformer (ViT) backbones into prototype based models, while offering spatially deformed prototypes that not only accommodate geometric variations of objects but also provide coherent and clear prototypical feature representations with an adaptive number of prototypical parts. Our experiments show that our model can generally achieve higher performance than the existing prototype based models. Our comprehensive analyses ensure that the prototypes are consistent and the interpretations are faithful.
研究动机与目标
- 在高风险领域凸显可解释图像分类器的需求。
- 开发一个以原型为基础的框架,使用 Vision Transformer 作为主干。
- 实现自适应、几何灵活的原型,并提供连贯、真实的解释。
- 提出一个训练过程,在最大化准确率的同时保持可解释性。
提出的方法
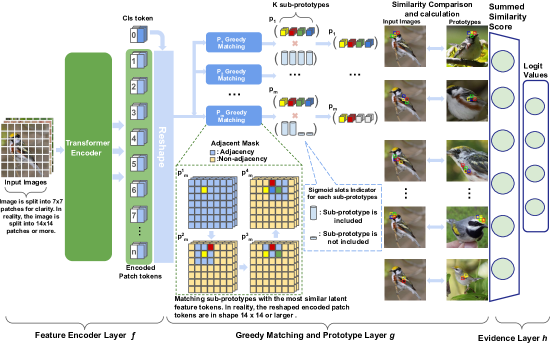
- 使用 ViT 主干作为特征编码器 f,从图像补丁中产生潜在令牌。
- 将原型定义为子原型集合,并应用贪婪匹配层 g 将子原型与潜在令牌配对。
- 纳入邻接掩码以确保子原型之间的几何连通性。
- 引入自适应槽机制以允许每个原型具有动态数量的子原型。
- 将原型投射到最近的潜在补丁以实现可视化解释,并优化证据层 h 以实现最终分类。
- 使用阶段性损失进行训练,包括聚类、分离、相干性和正交性项,随后进行原型裁剪和投影步骤。
实验结果
研究问题
- RQ1ProtoViT 是否在保持可解释性的前提下实现比现有原型基模型更高的准确性?
- RQ2自适应、可变形的原型是否能在不同数据集上产生连贯且真实的原型解释?
- RQ3ProtoViT 如何处理视觉推理中的几何变形和位置对齐问题?
- RQ4原型投影对模型性能和可解释性有何影响?
主要发现
| Architecture | Model | CUB Acc(%) | Car Acc(%) |
|---|---|---|---|
| ProtoPNet | (9) | 80.1 ± 0.3 | 89.5 ± 0.2 |
| Densenet-161 | Def. ProtoPNet(2x2) (given in [ 10 ] ) | 80.9 ± 0.22 | 88.7 ± 0.3 |
| ProtoPool | (13) | 80.3 ± 0.3 | 90.0 ± 0.3 |
| TesNet | (14) | 81.5 ± 0.3 | 92.6 ± 0.3 |
| Base | (given in [ 23 ] ) | 80.57 | 86.21 |
| DeiT-Tiny | ViT-Net (given in [ 23 ] ) | 81.98 | 88.41 |
| ProtoPFormer | (given in [ 23 ] ) | 82.26 | 88.48 |
| ProtoViT(K=4,r=1) | ours | 82.92 ± 0.5 | 89.02 ± 0.1 |
| Baseline | (given in [ 23 ] ) | 84.28 | 90.06 |
| DeiT-Small | ViT-Net (given in [ 23 ] ) | 84.26 | 91.34 |
| ProtoPFormer | (given in [ 23 ] ) | 84.85 | 90.86 |
| ProtoViT(K=4,r=1) | ours | 85.37 ± 0.13 | 91.84 ± 0.3 |
| Baseline | (given in [ 23 ] ) | 83.95 | 90.19 |
| CaiT-XXS 24 | ViT-Net (given in [ 23 ] ) | 84.51 | 91.54 |
| ProtoPFormer | (given in [ 23 ] ) | 84.79 | 91.04 |
| ProtoViT(K=4,r=1) | ours | 85.82 ± 0.15 | 92.40 ± 0.1 |
- 使用 ViT 主干的 ProtoViT 在鸟类和汽车数据集上取得比若干原型基方法更高的准确率。
- K=4 子原型且 r=1 邻接的 ProtoViT 在 CUB 达到 82.92% 的准确率,在 Car 数据集达到 89.02% 的准确率(DeiT 主干)。
- 使用 CaiT-XXS 主干的 ProtoViT 达到 85.82% 的 CUB 准确率和 92.40% 的 Car 准确率。
- ProtoViT 相对于使用相同主干的其他原型模型具有更高的准确性,并提供映射到实际图像补丁的可视化连贯原型。
- 全局/局部分析表明原型始终对应于有意义的语义特征。
- 位置错位基准显示 ProtoViT 在 PLC、PAC 和 PRC 方面的表现与 CNN 基原型模型相当或更好,同时保持有竞争力的准确性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。