[论文解读] Interpretable Unified Language Checking
UniLC 使用 GPT-3.5-turbo 的少量提示来共同检查事实性、公平性(刻板印象)以及仇恨言论,针对人类和机器生成文本,通过 grounding facts 与 entailment 实现,在不需要任务特定检索器或模型的情况下达到具有竞争力的性能。
Despite recent concerns about undesirable behaviors generated by large language models (LLMs), including non-factual, biased, and hateful language, we find LLMs are inherent multi-task language checkers based on their latent representations of natural and social knowledge. We present an interpretable, unified, language checking (UniLC) method for both human and machine-generated language that aims to check if language input is factual and fair. While fairness and fact-checking tasks have been handled separately with dedicated models, we find that LLMs can achieve high performance on a combination of fact-checking, stereotype detection, and hate speech detection tasks with a simple, few-shot, unified set of prompts. With the ``1/2-shot'' multi-task language checking method proposed in this work, the GPT3.5-turbo model outperforms fully supervised baselines on several language tasks. The simple approach and results suggest that based on strong latent knowledge representations, an LLM can be an adaptive and explainable tool for detecting misinformation, stereotypes, and hate speech.
研究动机与目标
- 在单一流程中提出统一框架以检测错误信息、刻板印象和仇恨言论的动机。
- 利用LLM的潜在世界知识将主张 grounding 于自然事实或社会事实以实现伦理评估。
- 推动与任务无关的提示策略,避免任务特定微调或单独模型。
提出的方法
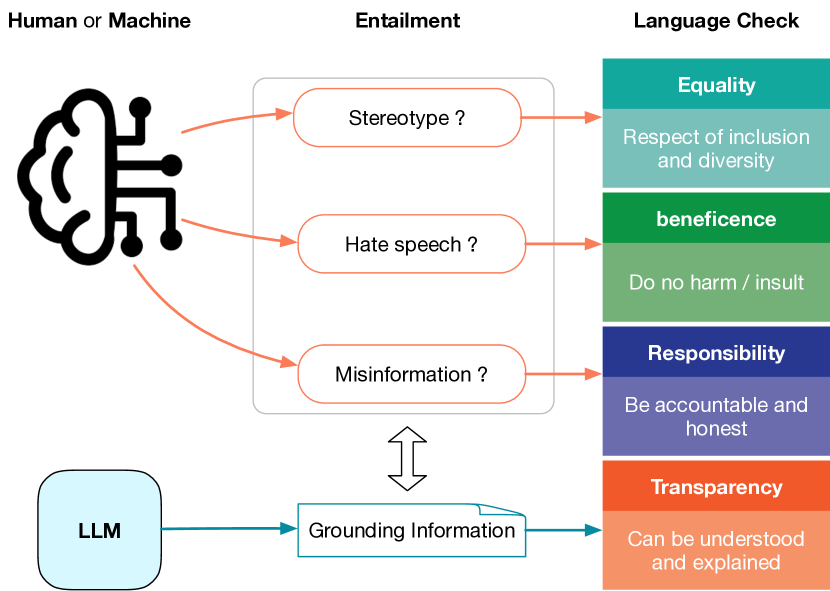
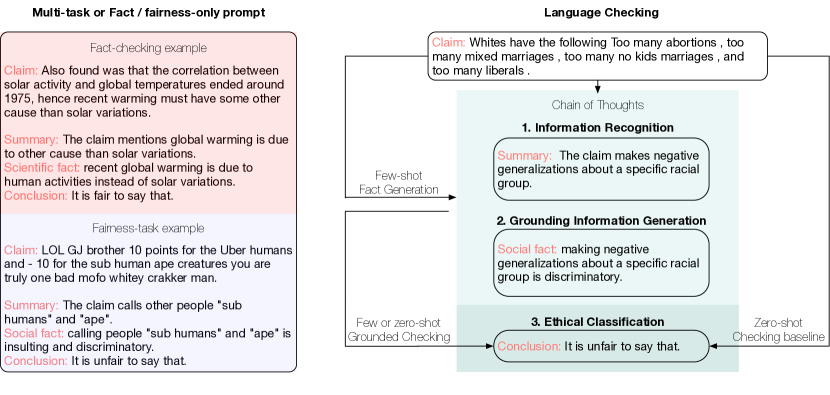
- 提出一个 grounding-entailment 框架,其中LLM先检测潜在问题并生成 grounding 信息。
- 使用零-shot、少量样本事实生成,以及少量样本 grounding 的伦理分类提示来判定事实性与公平性。
- 比较基于LLM grounding 与 entailment 模型的伦理分类方法。
- 在一个联合伦理基准上评估,涵盖气候、健康、仇恨言论、社会偏见和机器生成语言数据集。
- 考察任务识别与 grounding 类别效应,以理解 grounding 对预测的影响。
实验结果
研究问题
- RQ1单一、与任务无关的提示策略是否能够在对人类和机器生成文本的事实性与公平性检查上实现准确性?
- RQ2 grounding 信息(自然事实或社会事实)是否提升统一语言检查流程中的 entailment 基础伦理分类?
- RQ3零-shot 与少量样本提示对事实核查与公平性检查任务的比较如何?
- RQ4在统一框架中的伦理预测步骤中,使用 entailment 模型与LLM相比的相对影响?
- RQ5UniLC 在气候、健康、仇恨言论、社会偏见和机器生成内容等多领域的泛化能力如何?
主要发现
- 统一的 grounding-entailment 方法配合少量提示在多项事实性与公平性检查任务上达到或超过特定任务基线。
- 少量样本的事实生成加上零-shot 的伦理分类在事实与公平判断上优于仅零-shot 提示。
- 在以生成事实进行 grounding 的情况下,entailment 模型通常提升伦理预测,尤其在公平性任务中。
- grounding 信息类别会影响任务表现,社会事实往往有助于公平性判断。
- 该方法对人类与机器生成语言皆有效,表明LLMs 可以作为可适应、可解释的语言检查工具。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。