QUICK REVIEW
[论文解读] Invariant Risk Minimization
Martín Arjovsky, Léon Bottou|arXiv (Cornell University)|Jul 5, 2019
Domain Adaptation and Few-Shot Learning参考文献 51被引用 321
一句话总结
简要:IRM 提出学习数据表征,使其产生跨多个训练环境不变的预测器,通过将稳定的因果信号与伪相关分离来实现对分布外的泛化。
ABSTRACT
We introduce Invariant Risk Minimization (IRM), a learning paradigm to estimate invariant correlations across multiple training distributions. To achieve this goal, IRM learns a data representation such that the optimal classifier, on top of that data representation, matches for all training distributions. Through theory and experiments, we show how the invariances learned by IRM relate to the causal structures governing the data and enable out-of-distribution generalization.
研究动机与目标
- 动机并形式化在分布偏移和选择偏差下的泛化问题。
- 引入 IRM 作为一种范式,用以学习在各环境中支持不变预测器的表征。
- 提供将不变性、因果性与泛化联系起来的理论与算法基础。
- 展示实用方法并讨论局限性与未来方向。
提出的方法
- 定义环境和 IRM 目标,以找到在各环境下最小化风险的表征和固定分类器。
- 引入 IRMv1,作为通过梯度惩罚来促进不变性的实际放松形式。
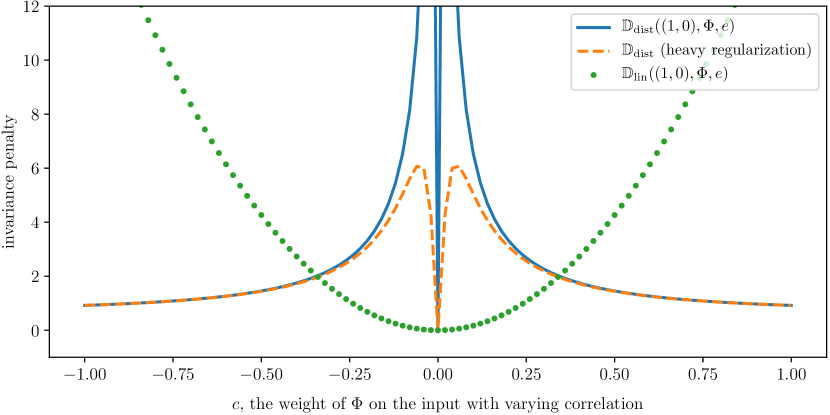
- 提出基于正规方程的线性不变性惩罚 D_lin,以避免不稳定的矩阵求逆。
- 表明在线性情形下,固定的标量分类器足以监测不变性,并扩展到非线性 Phi。
- 通过结构方程模型与干预将 IRM 与因果推断连接起来,提供转移到未见环境的条件。
实验结果
研究问题
- RQ1如何学习在多个训练环境中保持不变的预测器?
- RQ2在什么条件下从训练环境学得的不变性会转移到未见环境?
- RQ3在表示学习中强制不变性的算法和理论含义是什么?
- RQ4IRM 如何与因果性相关,这对分布外泛化意味着什么?
主要发现
- IRM 定义了一个实用目标,用以学习在各环境中产生不变预测器的表征。
- IRMv1 形式使用梯度惩罚来强制不变性,同时保留预测能力。
- 提出线性不变性惩罚 D_lin,用以稳健地衡量最优性条件的违反,而无需不稳定的求逆。
- 本工作通过 SEM 与干预将不变性与因果性联系起来,概述在何种条件下不变性意味着对分布外的泛化。
- IRM 表明跨训练环境的不变性可以在分布偏移下超越这些环境实现泛化。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。