[论文解读] Investigating the Effectiveness of Task-Agnostic Prefix Prompt for Instruction Following
这篇论文表明,在推理过程中在输入前附加一个固定的任务无关前缀提示(TAPP)可以提高指令遵从性,适用于基础模型和指令微调模型,在评估任务上的提升最高达到基模型34.58%、指令微调模型12.26%。该效应与微调无关,并在某些输入污染下仍然存在。
In this paper, we present our finding that prepending a Task-Agnostic Prefix Prompt (TAPP) to the input improves the instruction-following ability of various Large Language Models (LLMs) during inference. TAPP is different from canonical prompts for LLMs in that it is a fixed prompt prepended to the beginning of every input regardless of the target task for zero-shot generalization. We observe that both base LLMs (i.e. not fine-tuned to follow instructions) and instruction-tuned models benefit from TAPP, resulting in 34.58% and 12.26% improvement on average, respectively. This implies that the instruction-following ability of LLMs can be improved during inference time with a fixed prompt constructed with simple heuristics. We hypothesize that TAPP assists language models to better estimate the output distribution by focusing more on the instruction of the target task during inference. In other words, such ability does not seem to be sufficiently activated in not only base LLMs but also many instruction-fine-tuned LLMs. All experiments are reproducible from https://github.com/seonghyeonye/TAPP.
研究动机与目标
- 证明一个固定的、任务无关前缀在推理阶段能够提升跨越多样化LLM的指令遵从。
- 显示 TAPP 对基础模型和指令微调模型都能带来提升,并且与指令微调互补。
- 分析 TAPP 演示的构建规则及其对零-shot 与少-shot 泛化的影响。
- 研究 TAPP 对输入分布污染的鲁棒性及其与任务类别信号的关系。
提出的方法
- 使用简单启发式方法从跨任务演示(指令、输入、输出)构建一个固定的 TAPP 前缀。
- 将 M(TAPP 演示)置于目标任务的指令和输入之前,并通过 arg max P(y_ti|M,I_t,x_ti;θ) 计算 y_ti。
- 在 119 个未公开的 SuperNI 任务上跨 12 个类别使用多样化的 LLMs(GPT-3、OPT、GPT-NeoX、GPT-J)进行评估。
- 将 TAPP 与针对任务的前缀(Nearest PP、Category PP、Output PP)进行比较,并分析带有 TAPP 的少-shot 直接学习(few-shot ICL)。
- 通过将演示的输入替换为随机句子来研究对输入分布污染的鲁棒性。
实验结果
研究问题
- RQ1固定的、任务无关前缀在推理阶段是否能提升基础 LLMs 与指令微调 LLMs 的指令遵从?
- RQ2TAPP 的提升是否与指令微调和 RLHF 互补?
- RQ3TAPP 演示的哪些方面(指令、输入、输出)驱动其有效性?
- RQ4与带演示的前缀对比,TAPP 与任务特定前缀及带演示的少-shot 直接学习相比如何?
- RQ5TAPP 对演示输入污染的鲁棒性如何?
主要发现
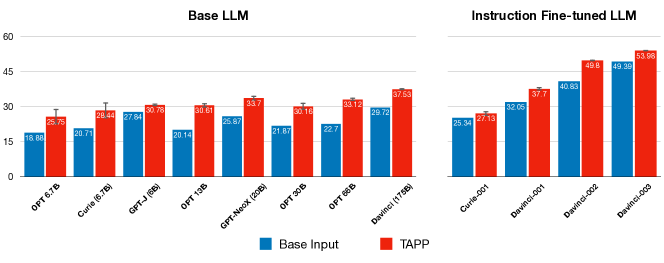
- TAPP 在基础 LLM 的表现随模型规模提升而持续改善,获得显著提升(例如,OPT-13B)。
- TAPP 能让较小的模型在没有 TAPP 的情况下也能超过更大模型(例如,6B 的 GPT-J 相较于 175B 的 GPT-3 无 TAPP)。
- TAPP 也提升了指令微调的 LLMs,尤其是参数超过 100B 的模型,并且可将顶尖模型(例如 text-davinci-003)的性能提升至多 9.3%。
- 来自 TAPP 的提升与指令微调正交且可与添加到 TAPP 的少-shot 演示一起工作;输入污染对性能的影响有限。
- 由带有明确答案选项的分类任务构建的演示尤为有效,避免跨演示的答案选项重叠有助于提升,尤其是在生成任务中。
- 由 ChatGPT 生成的 TAPP 演示与基准派生的演示带来相当的提升,表明该方法对演示来源具有鲁棒性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。