[论文解读] Is ChatGPT a Highly Fluent Grammatical Error Correction System? A Comprehensive Evaluation
本论文评估 ChatGPT (gpt-3.5-turbo) 在多语言和文档级任务中的语法错误纠正(GEC),使用零-shot 和少-shot 链式思考提示,并与 SOTA 模型及 Grammarly 进行比较。
ChatGPT, a large-scale language model based on the advanced GPT-3.5 architecture, has shown remarkable potential in various Natural Language Processing (NLP) tasks. However, there is currently a dearth of comprehensive study exploring its potential in the area of Grammatical Error Correction (GEC). To showcase its capabilities in GEC, we design zero-shot chain-of-thought (CoT) and few-shot CoT settings using in-context learning for ChatGPT. Our evaluation involves assessing ChatGPT's performance on five official test sets in three different languages, along with three document-level GEC test sets in English. Our experimental results and human evaluations demonstrate that ChatGPT has excellent error detection capabilities and can freely correct errors to make the corrected sentences very fluent, possibly due to its over-correction tendencies and not adhering to the principle of minimal edits. Additionally, its performance in non-English and low-resource settings highlights its potential in multilingual GEC tasks. However, further analysis of various types of errors at the document-level has shown that ChatGPT cannot effectively correct agreement, coreference, tense errors across sentences, and cross-sentence boundary errors.
研究动机与目标
- 使用多份官方测试集评估 ChatGPT 在英语、德语和中文的句子级 GEC 能力。
- 调查 使用 链式思考 提示 的 零-shot 与 少-shot 的 in-context 学习 在 GEC 的效果。
- 评估 ChatGPT 在英语文档级 GEC 的表现并分析错误类型。
- 进行自动和人工评估,以理解流畅性和编辑行为。
- 考察非英语及低资源语言的 GEC 表现,并识别优势与局限性。
提出的方法
- 设计用于 ChatGPT 的零-shot 与零-shot CoT 提示,以识别并纠正语法错误,同时保持句子结构。
- 开发带有在多个数据集上随机选取的上下文内示例的少-shot CoT 提示。
- 使用自动指标和人工评估,在英语、德语和中文的五个句子级测试集,以及三个英语文档级集,评估 ChatGPT。
- 在合适时,使用 M2 Scorer、ERRANT 和基于 GLUE 的指标,将 ChatGPT 与 Transformer-base、GECToR、T5-large 与 Grammarly 进行比较。
- 使用 ERRANT 对文档级 GEC 进行手动错误类型分析,以识别跨句子错误模式和局限性。

实验结果
研究问题
- RQ1在使用零-shot 和少-shot CoT 提示时,ChatGPT 在英语、德语和中文的句子级 GEC 上的表现如何?
- RQ2相比标准提示,链式思考提示是否提升 ChatGPT 的 GEC 表现?
- RQ3在标准基准测试和以流畅性为焦点的指标上,ChatGPT 如何与 SOTA GEC 系统与 Grammarly 相比?
- RQ4ChatGPT 在文档级 GEC 的优势与局限性是什么?它在哪些错误类型上较为吃力?
- RQ5ChatGPT 在非英语及低资源 GEC 设置中是否有效?
主要发现
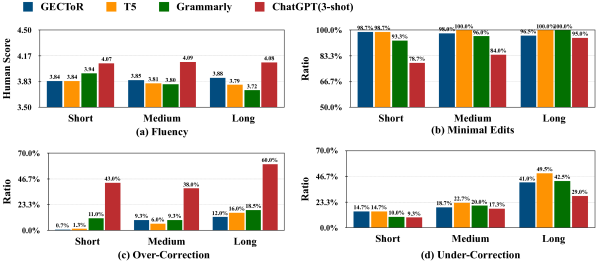
- 相较于 SOTA 模型,在句子级任务上,ChatGPT 实现了高召回率和较强的流畅性,但在精确度和 F0.5 方面较低。
- 少-shot CoT 提示通常优于零-shot CoT,3-shot 常居于最佳之列;超过五次提示可能降低表现。
- 在 JFLEG 的以流畅性为焦点的度量中,ChatGPT 的3-shot CoT 近似 SOTA,并且可能超越 T5-large,表明其强流畅性纠错。
- 在非英语及低资源语言中,ChatGPT 在召回方面能超越从头训练的 Transformer 基线,但在精确度和 F0.5 往往落后;表现因语言而异。
- 文档级 GEC 显示 ChatGPT 在召回和流畅性方面很强,但跨句子错误纠正(一致性、指称、时态)和跨句子边界处理较差。
- 自动化的人类评估显示,在某些设置下,ChatGPT 的流畅性可以接近甚至超过人类水平,但在最少改动的约束下,它可能仍与参考修正存在差异。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。