[论文解读] Is K-fold cross validation the best model selection method for Machine Learning?
简要:论文认为标准的 K-fold cross-validation 会放大假阳性并提出 K-fold Cross Upper Bounding Validation (CUBV) 来界定实际误差并提高 ML 的统计推断,尤其是在小型或异质的神经影像数据中。
As a technique that can compactly represent complex patterns, machine learning has significant potential for predictive inference. K-fold cross-validation (CV) is the most common approach to ascertaining the likelihood that a machine learning outcome is generated by chance, and it frequently outperforms conventional hypothesis testing. This improvement uses measures directly obtained from machine learning classifications, such as accuracy, that do not have a parametric description. To approach a frequentist analysis within machine learning pipelines, a permutation test or simple statistics from data partitions (i.e., folds) can be added to estimate confidence intervals. Unfortunately, neither parametric nor non-parametric tests solve the inherent problems of partitioning small sample-size datasets and learning from heterogeneous data sources. The fact that machine learning strongly depends on the learning parameters and the distribution of data across folds recapitulates familiar difficulties around excess false positives and replication. A novel statistical test based on K-fold CV and the Upper Bound of the actual risk (K-fold CUBV) is proposed, where uncertain predictions of machine learning with CV are bounded by the worst case through the evaluation of concentration inequalities. Probably Approximately Correct-Bayesian upper bounds for linear classifiers in combination with K-fold CV are derived and used to estimate the actual risk. The performance with simulated and neuroimaging datasets suggests that K-fold CUBV is a robust criterion for detecting effects and validating accuracy values obtained from machine learning and classical CV schemes, while avoiding excess false positives.
研究动机与目标
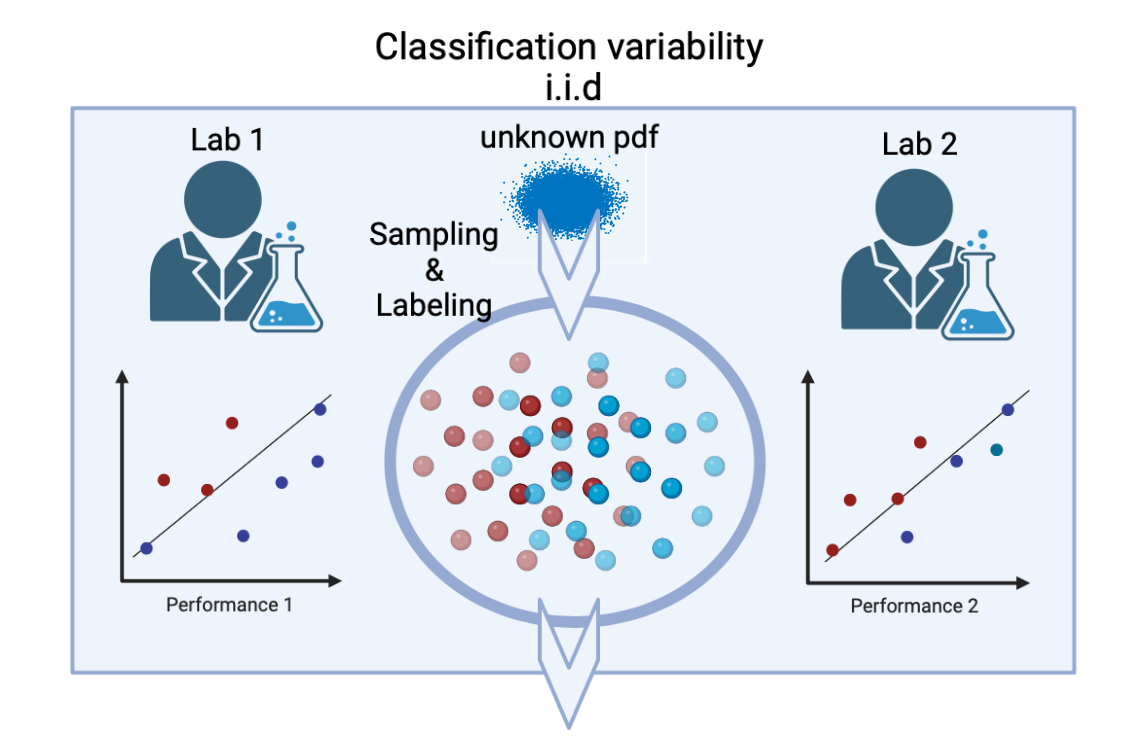
- 阐明在小型或异质数据集上进行假设检验时,标准 K-fold CV 的局限性。
- 提出一个统计学上有依据的方法,用于界定基于 CV 的 ML 分析中的实际误差。
- 在合成数据和来自 ADNI/MCI 的真实神经影像 MRI 数据集上评估所提方法。
- 评估数据异质性和样本量如何影响 ML 流水线中的预测推断与误差上界。“],
- method=[
- 引入 K-fold Cross Upper Bounding Validation (CUBV),它使用集中不等式在给定经验 CV 误差的情况下界定实际误差。
- 将 K-fold CV 与受 PAC-Bayesian 启发的上界结合,以推导错误分类风险的置信区间。
- 形式化一个统计检验(K-fold CUBV test),若 CV 基于的上界在概率 1−η 下达到指定阈值则拒绝原假设。
- 使用具有单簇与多簇高斯分布的合成数据来模拟异质性并评估 I 型错误控制。
- 将该方法应用于来自 ADNI/ADNI 派生特征的真实 MRI 多分类数据集,以验证发现。
实验结果
研究问题
- RQ1在小样本或异质样本中,基于 K-fold CV 的 ML 在置换检验下是否会产生膨胀的假阳性?
- RQ2K-fold CUBV 方法是否在不同的实验设计中提供对实际误差的有效上界?
- RQ3数据异质性和多簇结构如何影响神经影像分类任务中的预测推断?
- RQ4将 CV 与 PAC-Bayesian 上界结合是否比标准 CV 提高对 I 型错误的控制?
- RQ5所提出的方法在现实世界的 MRI/MCI 预测任务中是否实用且有效?
主要发现
- 单独的 K-fold CV 在某些零假设实验设置中可能产生超过名义水平的假阳性,尤其在样本量较小时。
- K-fold CUBV 在模拟的多样本和单样本实验中始终控制 I 型错误。
- CUBV 方法在某些情形下比标准 CV 的检出力低,但提供了稳健的误差界限和在异质性下改进的推断。
- 在仿真中,数据复杂度增加和样本量较小会提高 CV 表现的变异性,CUBV 有助于量化并界定这种变异。
- 将该方法应用于基于 MRI 的神经影像数据集,展示了在验证 ML 准确性的同时减轻过量假阳性的可行性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。