[论文解读] Is Mamba Capable of In-Context Learning?
本文提供实证证据表明 Mamba,一种选择性的结构化状态空间模型,在简单函数任务和 NLP 基准上的 in-context learning (ICL) 与 transformers 相当,并且在处理长输入序列时可能提供一种高效的替代方案。
State of the art foundation models such as GPT-4 perform surprisingly well at in-context learning (ICL), a variant of meta-learning concerning the learned ability to solve tasks during a neural network forward pass, exploiting contextual information provided as input to the model. This useful ability emerges as a side product of the foundation model's massive pretraining. While transformer models are currently the state of the art in ICL, this work provides empirical evidence that Mamba, a newly proposed state space model which scales better than transformers w.r.t. the input sequence length, has similar ICL capabilities. We evaluated Mamba on tasks involving simple function approximation as well as more complex natural language processing problems. Our results demonstrate that, across both categories of tasks, Mamba closely matches the performance of transformer models for ICL. Further analysis reveals that, like transformers, Mamba appears to solve ICL problems by incrementally optimizing its internal representations. Overall, our work suggests that Mamba can be an efficient alternative to transformers for ICL tasks involving long input sequences. This is an exciting finding in meta-learning and may enable generalizations of in-context learned AutoML algorithms (like TabPFN or Optformer) to long input sequences.
研究动机与目标
- 证明 Mamba 是否能够在简单函数类别和 NLP 任务中实现 in-context learning (ICL)。
- 将 Mamba 的 ICL 性能与 transformer 基线以及相关的 SSM 变体(如 S4)和 RWKV 进行比较。
- 研究 Mamba 解决 ICL 的机制,包括增量内部表示的优化。
- 评估在增加上下文长度和模型规模时 Mamba 的 ICL 可扩展性。
提出的方法
- 在简单回归任务分布(线性、偏斜 LR、带噪 LR、随机象限)上训练 Mamba 和基线,并在匹配参数数量下与 GPT-2/Transformer、S4、RWKV 进行比较。
- 评估简单函数类别上的 ICL 性能,并评估同分布内外的泛化。
- 使用探测(probe)策略分析 Mamba 是否通过类似变换器的迭代优化来解决 ICL,包括对中间表示的线性探测。
- 在 Pile 上对不同规模(130M 到 2.8B 参数)的 Mamba 语言模型进行预训练和微调;在 Hendel 等 NLP 任务上将 ICL 性能与 RWKV 及常见 transformers 进行比较。
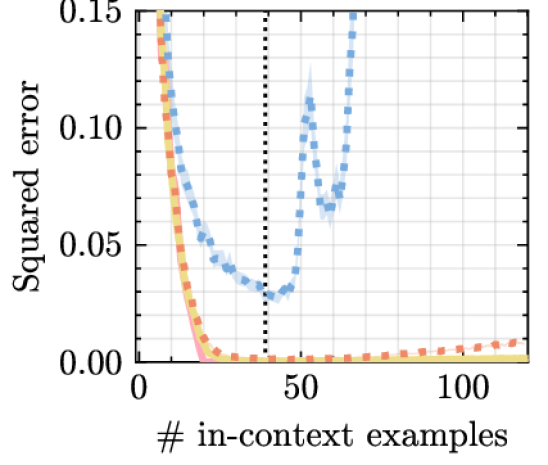
实验结果
研究问题
- RQ1Mamba 是否能够在简单回归任务上达到与 transformer 相当的 ICL 性能,并推断到更长的输入序列?
- RQ2Mamba 是否通过类似 transformers 的增量内部表示优化来实现 ICL?
- RQ3在 NLP 基准测试中,Mamba 的 ICL 性能如何随模型规模和上下文长度的增加而扩展?
主要发现
- 在若干简单函数类别和 NLP 任务的 ICL 中,Mamba 与 transformer 性能相当。
- 在所有测试设定中,Mamba 在 ICL 方面优于 S4 和 RWKV 基线。
- 探测结果表明 Mamba 与 transformers 在 ICL 期间采用迭代优化式的机制来改进解。
- 在 NLP 任务中,Mamba 模型规模更大、上下文更长时 ICL 性能提升。
- Mamba 在线性回归上的对更长输入的外推能力强,并在 NLP 基准中保持有竞争力的准确性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。