[论文解读] Jump to Conclusions: Short-Cutting Transformers With Linear Transformations
This paper learns layer-to-layer linear mappings to cast hidden transformer representations, enabling better approximations of final-layer outputs and improving efficiency in early exiting and sub-module linear approximations.
Transformer-based language models create hidden representations of their inputs at every layer, but only use final-layer representations for prediction. This obscures the internal decision-making process of the model and the utility of its intermediate representations. One way to elucidate this is to cast the hidden representations as final representations, bypassing the transformer computation in-between. In this work, we suggest a simple method for such casting, using linear transformations. This approximation far exceeds the prevailing practice of inspecting hidden representations from all layers, in the space of the final layer. Moreover, in the context of language modeling, our method produces more accurate predictions from hidden layers, across various model scales, architectures, and data distributions. This allows "peeking" into intermediate representations, showing that GPT-2 and BERT often predict the final output already in early layers. We then demonstrate the practicality of our method to recent early exit strategies, showing that when aiming, for example, at retention of 95% accuracy, our approach saves additional 7.9% layers for GPT-2 and 5.4% layers for BERT. Last, we extend our method to linearly approximate sub-modules, finding that attention is most tolerant to this change. Our code and learned mappings are publicly available at https://github.com/sashayd/mat.
研究动机与目标
- Motivate interpretability and efficiency gains from using intermediate transformer representations rather than only final-layer representations.
- Propose a lightweight linear mapping (mat) to transform hidden states from any earlier layer to a later layer.
- Evaluate how well mat approximates final-layer representations and predictions across GPT-2 and BERT on multiple data sources.
- Demonstrate practical benefits for early exiting and for approximating sub-modules like attention, FFN, and layer norms.
提出的方法
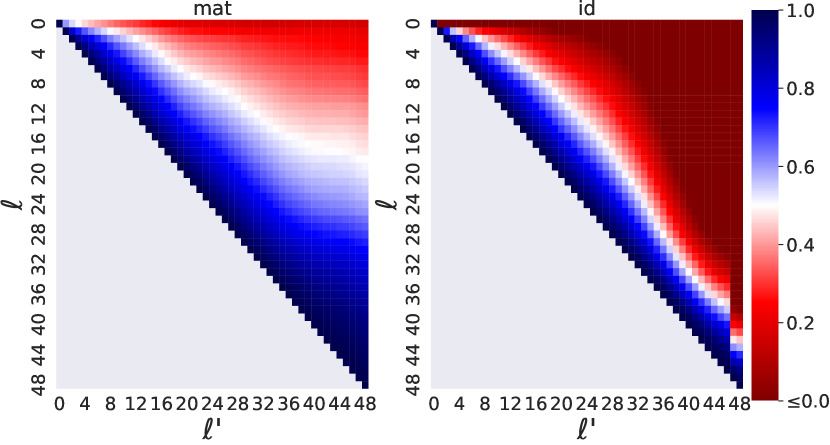
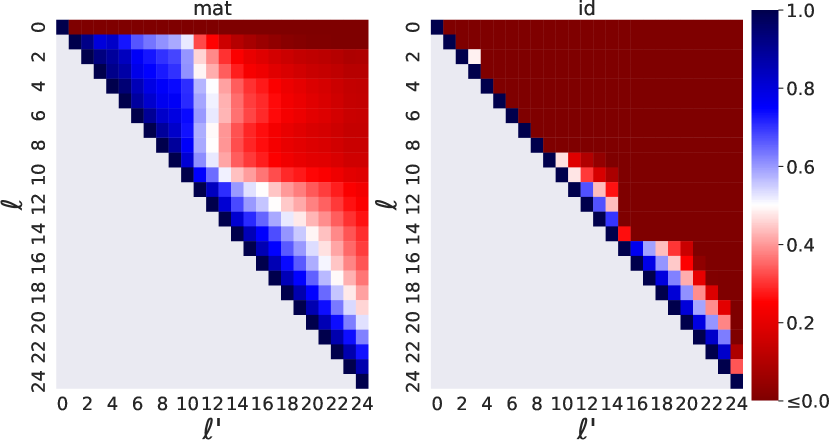
- 对于任意层对 ell < ell',通过最小化从模型运行序列得到的隐藏状态对上的回归损失,学习一个 d_h x d_h 的矩阵 A_{ell',ell}。
- 将 mat_{ell→ell'} 与仅原样传播表示的基线身份映射进行比较。
- 使用坐标逐项的 R^2 来衡量 mat(h^{ell}) 与真实 h^{ell'} 的近似质量。
- 将所学映射应用于下一个标记和掩码标记预测任务,以通过 Precision@k 和 surprisal 评估预测对齐。
- 将线性捷径扩展为替换子模块(注意力、FFN、层归一化)为线性近似,并评估对预测精度的影响。
- 通过在动态退出决策中用 mat 替换恒等映射来演示 mat 在早期退出中的实用性,并比较计算节省。
实验结果
研究问题
- RQ1一个简单的线性映射在变换器层之间是否能提供比常见的身份传播更准确的最终层表示替代?
- RQ2此类映射在下一个标记和掩码标记任务中能在多大程度上保留模型的预测分布?
- RQ3线性捷径是否在早期退出和替换子模块(如注意力、FFN 或层归一化)方面带来有意义的效率提升?
主要发现
- Mat 在 GPT-2 和 BERT 的 R^2 得分普遍高于身份基线,尤其在 BERT 情况下身份映射往往无法跨层映射。
- 在语言建模任务中,mat 相对于 id 提高了 Prediction@k 并降低了 Surprisal,且在早期层(如 GPT-2 的前 44 层)显著提升准确性。
- 使用 mat 进行早期退出比以往方法节省更多层,例如额外节省了 GPT-2 的 7.9% 层和 BERT 的 5.4% 层以达到 95% 的准确率。
- 该方法揭示早期表示往往已经对最终预测具有有意义的编码,在早期层(如最高1% 精度的 0.28–0.45 的 top-1 Precision 等)就可观察到非平凡的预测对齐。
- 线性近似子模块显示注意力对线性替换的容忍度最高,而 FFN 和层归一化则更为敏感,但在许多情况下也可以线性近似。
- 将子模块替换为线性捷径在某些层上可以实现而不致致灾难性损失,显示潜在的并行化计算收益。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。