[论文解读] Knowledge Diffusion for Distillation
DiffKD 使用通过教师特征训练的扩散模型对学生特征进行去噪,以弥合教师-学生差距,从而在视觉任务中实现更高效的知识蒸馏。
The representation gap between teacher and student is an emerging topic in knowledge distillation (KD). To reduce the gap and improve the performance, current methods often resort to complicated training schemes, loss functions, and feature alignments, which are task-specific and feature-specific. In this paper, we state that the essence of these methods is to discard the noisy information and distill the valuable information in the feature, and propose a novel KD method dubbed DiffKD, to explicitly denoise and match features using diffusion models. Our approach is based on the observation that student features typically contain more noises than teacher features due to the smaller capacity of student model. To address this, we propose to denoise student features using a diffusion model trained by teacher features. This allows us to perform better distillation between the refined clean feature and teacher feature. Additionally, we introduce a light-weight diffusion model with a linear autoencoder to reduce the computation cost and an adaptive noise matching module to improve the denoising performance. Extensive experiments demonstrate that DiffKD is effective across various types of features and achieves state-of-the-art performance consistently on image classification, object detection, and semantic segmentation tasks. Code is available at https://github.com/hunto/DiffKD.
研究动机与目标
- 在知识蒸馏中,针对由于容量差异引起的教师与学生表示能力差距提出动机并解决。
- 提出一个基于扩散的去噪模块,从学生特征中提取有价值的信息。
- 引入一个带线性自编码器的轻量级扩散模型以降低计算量。
- 增加一个自适应噪声匹配机制以对齐初始扩散噪声水平。
- 展示该方法在分类、检测和分割任务中的有效性。
提出的方法
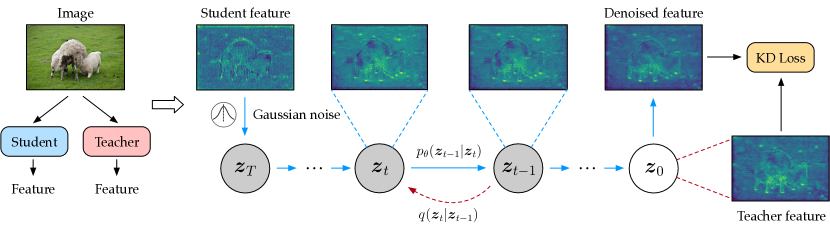
- 将学生特征视为教师特征的嘈杂版本,在教师特征上训练扩散模型以去噪学生特征。
- 使用去噪后的学生特征对教师特征进行蒸馏,采用标准的 KD 损失。
- 结合带有两个瓶颈块和线性自编码器的轻量级扩散架构,以压缩特征表示。
- 引入自适应噪声匹配模块,用于估计并注入合适的高斯噪声以初始化。
- 对扩散和蒸馏损失使用标准距离(MSE、KL),并提供使用高级 KD 损失的选项(如 DIST、DKD)。
- 用组合损失优化整个流程:Ltrain = Ltask + lambda1 Ldiff + lambda2 Lae + lambda3 Ldiffkd。
实验结果
研究问题
- RQ1如何利用扩散模型去噪并对齐教师与学生特征以进行KD?
- RQ2对学生特征进行去噪是否比跨任务的直接特征匹配带来更好的知识迁移?
- RQ3轻量级扩散模型和自适应噪声匹配能否在不造成过高成本的前提下实现实际收益?
- RQ4DiffKD 方法在特征类型(中间特征、logits)和任务(分类、检测、分割)上是否具有通用性?
主要发现
- DiffKD 在各任务上持续带来SOTA级的提升,例如在 ImageNet 上,MobileNetV1 学生与 ResNet-50 教师的 top-1 准确率为 73.62%。
- 在更强的教师设置下,DiffKD 在 Swin-T/Swin-L 及 ResNet 变体等模型对上超过了先前的 KD 方法。
- DiffKD 在多项基线上提升检测和分割基准,并且在简单的 KD 损失(MSE、KL)下仍然有效。
- 带线性自编码器的轻量级扩散模型在显著降低 FLOPs 的同时,保持或提升蒸馏性能。
- 自适应噪声匹配(ANM)通过将初始扩散噪声对齐到学生特征来提升去噪效果。
- 消融实验表明,结合特征和 logits 的 DiffKD 能获得最佳性能(例如,在某一设置下达到 73.62%)。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。