[论文解读] Language Agents with Reinforcement Learning for Strategic Play in the Werewolf Game
该论文提出一个框架,将大语言模型与强化学习结合,用于为Werewolf构建策略性语言代理,解决内在偏见与隐性信息推断问题,并在性能上优于包括人类水平在内的基线。
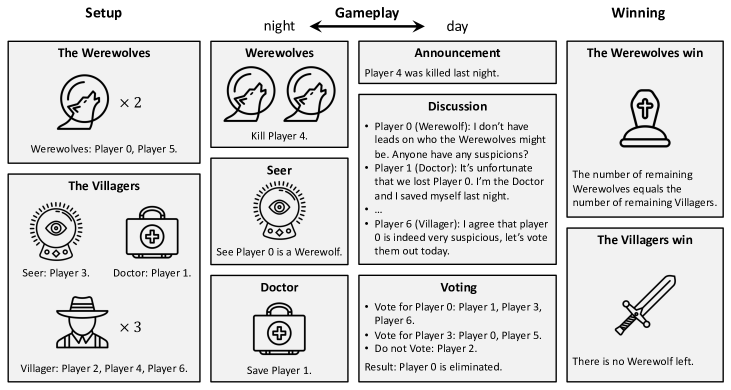
Agents built with large language models (LLMs) have shown great potential across a wide range of domains. However, in complex decision-making tasks, pure LLM-based agents tend to exhibit intrinsic bias in their choice of actions, which is inherited from the model's training data and results in suboptimal performance. To develop strategic language agents, i.e., agents that generate flexible language actions and possess strong decision-making abilities, we propose a novel framework that powers LLM-based agents with reinforcement learning (RL). We consider Werewolf, a popular social deduction game, as a challenging testbed that emphasizes versatile communication and strategic gameplay. To mitigate the intrinsic bias in language actions, our agents use an LLM to perform deductive reasoning and generate a diverse set of action candidates. Then an RL policy trained to optimize the decision-making ability chooses an action from the candidates to play in the game. Extensive experiments show that our agents overcome the intrinsic bias and outperform existing LLM-based agents in the Werewolf game. We also conduct human-agent experiments and find that our agents achieve human-level performance and demonstrate strong strategic play.
研究动机与目标
- 促使开发能够在社交推理游戏中进行复杂决策的策略性语言代理。
- 通过多样化行动生成和强化学习来解决纯LLM代理的内在偏见。
- 实现隐性角色推断以应对欺骗信息并改进后续决策。
提出的方法
- 隐藏角色推断:使用LLM来组织观测,分类真实与欺骗,并生成属性(角色、可靠性、推理、证据)。
- 多样化行动生成:通过常规提示或迭代提示生成多个行动候选(N),以减少行动偏见并丰富策略多样性。
- 基于群体的RL训练:学习一个轻量级策略,在自我注意力网络中对来自LLM嵌入的语言行动候选进行选择;通过对多样代理群体进行对抗训练以提升鲁棒性。
- 行动选择:使用LLM嵌入API对观测与候选进行向量化,利用保留自注意编码器计算一个与观测嵌入与候选嵌入的缩放点积成正比的概率。

实验结果
研究问题
- RQ1我们如何在玩复杂语言游戏时克服纯LLM代理的内在偏见?
- RQ2将LLM推理与学习到的RL策略结合,是否能改善Werewolf中的策略性决策?
- RQ3生成多样化的语言行动加上基于群体的训练,是否对对手多样性具有更鲁棒的策略?
主要发现
- 提出的RL框架的代理克服了内在偏见,展现出比纯LLM代理更均匀、更具策略性的行动分布。
- 在轮换对战中,策略性语言代理在Villagers和Werewolves两方对多项基线时取得最高胜率。
- 人机对比实验显示代理的胜率与人类相当,在某些设定甚至超过人类表现。
- 消融实验表明三个组成部分——隐藏角色推断、多样化行动生成和基于群体的RL——都对性能提升有贡献,且RL策略对克服偏见至关重要。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。