[论文解读] Language Instructed Reinforcement Learning for Human-AI Coordination
论文介绍了 instructRL,一个框架,使用自然语言指令和大型语言模型来正则化多智能体强化学习,使人工智能伙伴与人类协同朝向人类对齐的均衡,在 Say-Select 和 Hanabi 中得到实现。
One of the fundamental quests of AI is to produce agents that coordinate well with humans. This problem is challenging, especially in domains that lack high quality human behavioral data, because multi-agent reinforcement learning (RL) often converges to different equilibria from the ones that humans prefer. We propose a novel framework, instructRL, that enables humans to specify what kind of strategies they expect from their AI partners through natural language instructions. We use pretrained large language models to generate a prior policy conditioned on the human instruction and use the prior to regularize the RL objective. This leads to the RL agent converging to equilibria that are aligned with human preferences. We show that instructRL converges to human-like policies that satisfy the given instructions in a proof-of-concept environment as well as the challenging Hanabi benchmark. Finally, we show that knowing the language instruction significantly boosts human-AI coordination performance in human evaluations in Hanabi.
研究动机与目标
- Enable AI partners to coordinate with humans by guiding equilibrium selection through natural language instructions.
- Leverage pretrained language models to generate a prior policy conditioned on human instructions.
- Regularize RL training with the LLM prior to converge to human-preferred equilibria.
- Demonstrate the approach in a designed Say-Select game and the Hanabi benchmark.
- Show through human evaluations that language-informed agents improve coordination when instructions are known.
提出的方法
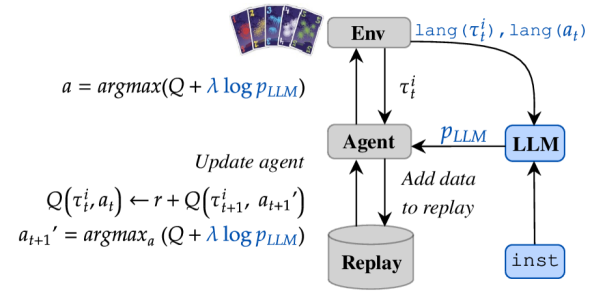
- Construct an LLM-based prior policy conditioned on the human instruction and current observation description.
- Map actions and observations to language descriptions to query the LLM for plausible actions.
- Regularize Q-learning and PPO with the LLM prior via log-probability augmentation or KL penalty.
- Show that instructRL can steer toward equilibria that satisfy the language instructions.
- Provide two concrete algorithmic instantiations: instructQ (Q-learning with log pLLM) and instructPPO (PPO with KL to pLLM).
- Apply parallel training and anneal the regularization weight to integrate the LLM guidance during RL.
实验结果
研究问题
- RQ1Can natural language instructions steer multi-agent RL toward human-preferred equilibria in cooperative tasks?
- RQ2Does conditioning policy learning on LLM priors lead to human-compatible policies in Say-Select and Hanabi?
- RQ3Do agents trained with language-guided regularization improve human-AI coordination compared to standard MARL baselines?
- RQ4Are the resulting policies interpretable and align with the given instructions in different environments?
主要发现
| 方法 | 自对弈 | 内部AXP |
|---|---|---|
| Q-learning | 23.96 ± 0.05 | 23.77 ± 0.07 |
| InstructQ (color) | 23.78 ± 0.05 | 23.77 ± 0.06 |
| InstructQ (rank) | 23.92 ± 0.02 | 23.78 ± 0.05 |
| PPO | 24.25 ± 0.01 | 24.25 ± 0.01 |
| InstructPPO (color) | 24.25 ± 0.03 | 24.23 ± 0.01 |
| InstructPPO (rank) | 24.10 ± 0.02 | 24.08 ± 0.02 |
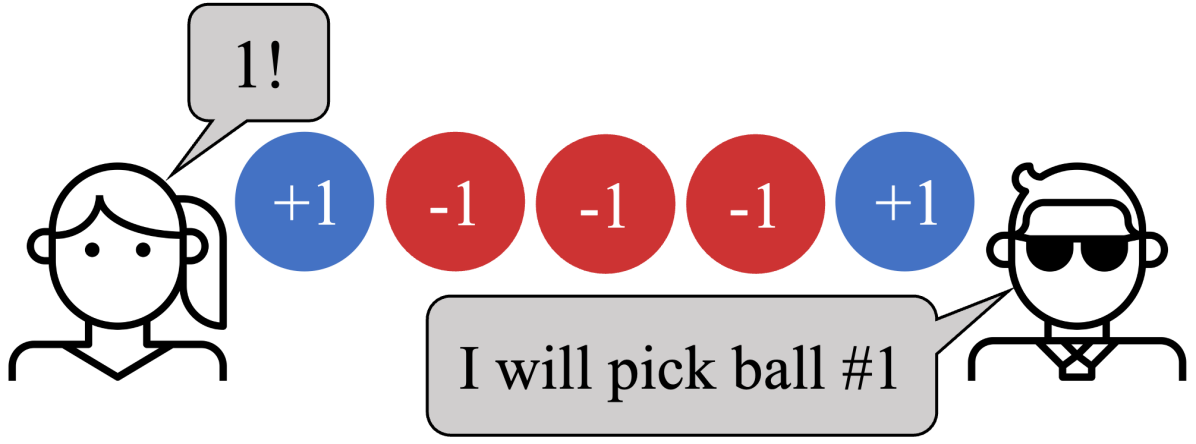
- In Say-Select, instructQ yields a policy aligned with the instruction “I should select the same number as my partner.”
- In Hanabi, instructQ and instructPPO produce semantically different policies (color-based vs rank-based) as dictated by the instruction.
- Both instructQ and instructPPO achieve self-play and intra-AXP performance comparable to vanilla baselines, indicating robust convergence.
- Human evaluation shows coordinating with language-informed agents improves performance when the instruction is known to humans.
- The method demonstrates that giving agents language-based guidance can steer equilibria without requiring large human demonstration datasets.
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。