[论文解读] Language Modeling Is Compression
本论文通过无损压缩重新框定预测问题,显示大语言模型作为通用预测器,在文本、图像和音频的上下文压缩方面表现出色,并分析了扩展、标记化以及将压缩器用作生成模型。
It has long been established that predictive models can be transformed into lossless compressors and vice versa. Incidentally, in recent years, the machine learning community has focused on training increasingly large and powerful self-supervised (language) models. Since these large language models exhibit impressive predictive capabilities, they are well-positioned to be strong compressors. In this work, we advocate for viewing the prediction problem through the lens of compression and evaluate the compression capabilities of large (foundation) models. We show that large language models are powerful general-purpose predictors and that the compression viewpoint provides novel insights into scaling laws, tokenization, and in-context learning. For example, Chinchilla 70B, while trained primarily on text, compresses ImageNet patches to 43.4% and LibriSpeech samples to 16.4% of their raw size, beating domain-specific compressors like PNG (58.5%) or FLAC (30.3%), respectively. Finally, we show that the prediction-compression equivalence allows us to use any compressor (like gzip) to build a conditional generative model.
研究动机与目标
- 通过无损压缩与信息理论的视角激发研究基础模型的动机。
- 对大型语言模型在多模态中的离线(上下文内)压缩能力进行实证评估。
- 分析扩展规律以及上下文长度和模型规模对压缩性能的影响。
- 展示如何将压缩器重新用作条件生成模型。
- 考察标记化与数据模态在压缩效率中的作用。
提出的方法
- 使用带有变换器与类Chinchilla模型的概率预测进行算术编码,以创建无损压缩器。
- 在文本(enwik9)、图像(ImageNet 块)和音频(LibriSpeech)上对1 GB样本进行压缩评估。
- 与通用压缩器(gzip、LZMA2)和领域特定压缩器(PNG、FLAC)进行比较。
- 研究模型大小与数据集大小的权衡,以实现最佳的调整后压缩率。
- 演示如何从压缩器中采样,作为在先前序列条件下的生成模型。
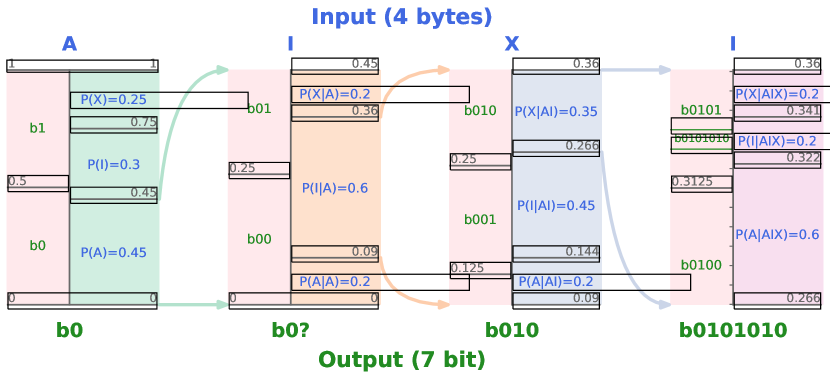
实验结果
研究问题
- RQ1基础模型是否主要在文本上训练,却能作为跨多模态的通用压缩器?
- RQ2上下文长度和模型规模如何影响上下文内压缩性能?
- RQ3标记化方案在与大模型结合时,是提升还是削弱了压缩?
- RQ4压缩器能否作为文本、图像和音频数据的条件生成模型使用?
- RQ5对于压缩性能与数据规模,缩放规律有什么影响?
主要发现
| 块大小 | 压缩器 | enwik9 原始 (%) | ImageNet 原始 (%) | LibriSpeech 原始 (%) | 随机原始 (%) | enwik9 调整后 (%) | ImageNet 调整后 (%) | LibriSpeech 调整后 (%) | 随机调整后 (%) |
|---|---|---|---|---|---|---|---|---|---|
| ∞ | gzip | 32.3 | 70.7 | 36.4 | 100.0 | 32.3 | 70.7 | 36.4 | 100.0 |
| ∞ | LZMA2 | 23.0 | 57.9 | 29.9 | 100.0 | 23.0 | 57.9 | 29.9 | 100.0 |
| ∞ | PNG | 42.9 | 58.5 | 32.2 | 100.0 | 42.9 | 58.5 | 32.2 | 100.0 |
| ∞ | FLAC | 89.5 | 61.9 | 30.9 | 107.8 | 89.5 | 61.9 | 30.9 | 107.8 |
| 2048 | gzip | 48.1 | 68.6 | 38.5 | 100.1 | 48.1 | 68.6 | 38.5 | 100.1 |
| 2048 | LZMA2 | 50.0 | 62.4 | 38.2 | 100.0 | 50.0 | 62.4 | 38.2 | 100.0 |
| 2048 | PNG | 80.6 | 61.7 | 37.6 | 103.2 | 80.6 | 61.7 | 37.6 | 103.2 |
| 2048 | FLAC | 88.9 | 60.9 | 30.3 | 107.2 | 88.9 | 60.9 | 30.3 | 107.2 |
| 200K | Transformer | 30.9 | 194.0 | 146.6 | 195.5 | 30.9 | 194.0 | 146.6 | 195.5 |
| 800K | Transformer | 21.9 | 185.3 | 131.3 | 200.3 | 21.9 | 185.3 | 131.3 | 200.3 |
| 3.2M | Transformer | 17.7 | 216.5 | 228.9 | 224.7 | 17.7 | 216.5 | 228.9 | 224.7 |
| 1B | Chinchilla | 211.3 | 262.2 | 224.9 | 308.8 | 1410.2 | 1454.7 | 1423.6 | 1501.6 |
| 7B | Chinchilla | 1410.2 | 1454.7 | 1423.6 | 1501.6 | 1410.2 | 1454.7 | 1423.6 | 1501.6 |
| 70B | Chinchilla | 14008.3 | 14048.0 | 14021.0 | 14100.8 | 14008.3 | 14048.0 | 14021.0 | 14100.8 |
- Chinchilla 70B 在 ImageNet 块上实现 43.4% 的压缩,在 LibriSpeech 上实现 16.4%,在各自领域超越了 PNG 和 FLAC。
- 大型基础模型提供强大的上下文学习,使文本、图像和音频的离线压缩具备竞争力。
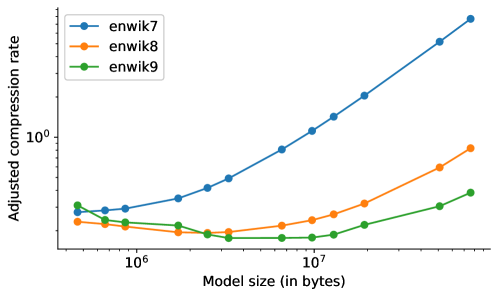
- 压缩性能遵循扩展规律,但受数据集规模限制;达到某一点后,增加参数会由于对模型大小的计入而提高调整后的压缩率。
- 标记化通常不会显著改善小模型的原始压缩率;对更大模型而言,较大的词汇表可能降低性能。
- 通过以先前上下文为条件并根据条件压缩长度差进行采样,将压缩器作为生成模型是可行的。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。