[论文解读] Language Models Represent Space and Time
这篇论文表明 Llama-2 和 Pythia 语言模型学习了线性、多尺度的时空表示,包括可识别的时空神经元,暗示从下一个标记预测中学到的初步世界模型。
The capabilities of large language models (LLMs) have sparked debate over whether such systems just learn an enormous collection of superficial statistics or a set of more coherent and grounded representations that reflect the real world. We find evidence for the latter by analyzing the learned representations of three spatial datasets (world, US, NYC places) and three temporal datasets (historical figures, artworks, news headlines) in the Llama-2 family of models. We discover that LLMs learn linear representations of space and time across multiple scales. These representations are robust to prompting variations and unified across different entity types (e.g. cities and landmarks). In addition, we identify individual "space neurons" and "time neurons" that reliably encode spatial and temporal coordinates. While further investigation is needed, our results suggest modern LLMs learn rich spatiotemporal representations of the real world and possess basic ingredients of a world model.
研究动机与目标
- 研究大型语言模型是否在超越表面统计的层面学习到连贯的时空表示。
- 提取并分析内部激活,以映射空间坐标(纬度/经度)和时间坐标(时间戳)。
- 评估这些表示在尺度和实体类型上的线性度、鲁棒性以及跨实体的一致性。
- 识别与空间和时间相关的单个神经元,以确立模型确实使用了这些特征。
提出的方法
- 构建六个多尺度的空间与时间相关实体数据集(世界、美国、纽约市;历史人物;艺术;头条新闻)。
- 在 Llama-2 和 Pythia 模型的各层的最后一个标记激活上运行线性 Ridge 探测,以预测真实世界的坐标(纬度/经度)或时间戳。
- 用 R^2 和 Spearman 相关系数评估探测,并使用近似误差来考虑局部地理精度。
- 通过与非线性探测器(MLP)比较来测试线性性,以确认空间/时间特征的可解码性。
- 通过改变提示词来评估提示对探测性能的影响,并观察跨数据集的探测表现。
- 通过将激活投影到探测方向并分析神经元权重,识别“空间神经元”和“时间神经元。”

实验结果
研究问题
- RQ1LLM 是否在内部表示中编码空间和时间信息?
- RQ2空间和时间表示是否在中到后层激活中呈线性且可解码?
- RQ3这些时空表示对提示变异是否鲁棒,并且是否跨实体类型统一?
- RQ4LLM 中的单个神经元是否编码空间或时间坐标,表明对这些特征的分布式使用?
主要发现
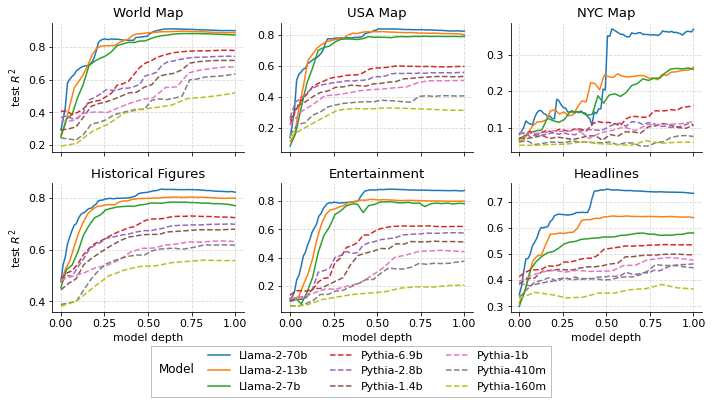
- 空间和时间特征可以通过跨层和跨尺度的线性探测器恢复。
- 表示在早期到中间层提升,在模型中点附近达到平台期,且较大模型表现更好。
- 非线性探测对线性探测几乎没有改进,支持空间/时间的线性可解性。
- 提示对探测性能影响有限,而随机标记可能降低性能;头条新闻后的句点标记可提高性能。
- 空间和时间表示在不同实体类型(城市与地标)之间具备泛化能力,且单个神经元与探测方向对齐,表明确实使用了这些特征。
- 即使通过 PCA 降维后数据也仍然具有探测信息,表明存在稳健的潜在时空结构。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。