[论文解读] Large image datasets: A pyrrhic win for computer vision?
本论文对 ImageNet 及相关大规模视觉数据集进行批判性审计,揭示数据来源、标注与隐私方面的伦理越界;提供定量普查并提出基于审计的改进方案。
In this paper we investigate problematic practices and consequences of large scale vision datasets. We examine broad issues such as the question of consent and justice as well as specific concerns such as the inclusion of verifiably pornographic images in datasets. Taking the ImageNet-ILSVRC-2012 dataset as an example, we perform a cross-sectional model-based quantitative census covering factors such as age, gender, NSFW content scoring, class-wise accuracy, human-cardinality-analysis, and the semanticity of the image class information in order to statistically investigate the extent and subtleties of ethical transgressions. We then use the census to help hand-curate a look-up-table of images in the ImageNet-ILSVRC-2012 dataset that fall into the categories of verifiably pornographic: shot in a non-consensual setting (up-skirt), beach voyeuristic, and exposed private parts. We survey the landscape of harm and threats both society broadly and individuals face due to uncritical and ill-considered dataset curation practices. We then propose possible courses of correction and critique the pros and cons of these. We have duly open-sourced all of the code and the census meta-datasets generated in this endeavor for the computer vision community to build on. By unveiling the severity of the threats, our hope is to motivate the constitution of mandatory Institutional Review Boards (IRB) for large scale dataset curation processes.
研究动机与目标
- 评估像 ImageNet-ILSVRC-2012 这类大规模视觉数据集的伦理含义与社会危害。
- 通过对年龄、性别、NSFW 内容、类别语义和准确性等的横截面普查来量化数据治理问题。
- 提出纠正策略与治理机制,以减轻在 LSVD 整理中的危害。
- 将普查数据集与代码开源,以便社区审计与透明。
提出的方法
- 对 ImageNet-ILSVRC-2012 在年龄、性别、NSFW 内容、类别准确性与语义性方面进行横截面模型化普查。
- 手动整理一个查找表,以在 ImageNet-ILSVRC-2012 中识别可证实为色情或非自愿的图像。
- 使用预训练模型(DEX、InsightFace、RetinaFace、ArcFace)对隐私丧失、反向图片搜索风险、性别偏见等危害进行审计与可视化。
- 汇编数据集审计卡及随附的元数据集(CSV 资源),以支持透明度与可重复性。
- 将代码和普查数据集开源,以便计算机视觉社区进行更广泛的审计。
实验结果
研究问题
- RQ1在多大程度上,大规模视觉数据集中包含伦理上有问题的图像(例如可证实的色情、非自愿或有害的标签)?
- RQ2与 ImageNet 及相关 LSVDs 相关的下游隐私、同意与偏见风险是什么?
- RQ3量化普查如何为减缓数据集整理中的危害的程序提供信息?
- RQ4哪些治理与审计机制(如数据集审计卡)可以提升 LSVDs 的透明度与伦理性?
主要发现
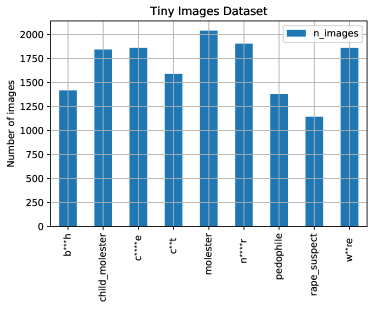
- ImageNet 在若干类别中包含非自愿和潜在剥削性的图像,手工整理的发现指出了厌女和色情内容。
- 针对 61 个类别参数的 57 项指标的普查揭示了与数量、年龄、性别、NSFW 分值和语义性相关的分布,凸显偏见与隐私问题。
- 研究记录了基于 WordNet 的类别分类法和标注实践中的伦理越界,传播刻板印象与隐私风险。
- 反向图片搜索和不透明数据集(如 JFT-300M、Open Images、Tiny Images)使现实世界中的识别和隐私危害成为可能。
- 作者提供开源数据集与教程,以促进持续审计,并倡导对 LSVD 整理设立机构审查板(IRB)。
- ImageNet 的一个审计卡示例总结了该数据集的已知不足及相关风险。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。