[论文解读] Large Language Model Unlearning
该论文提出将忘记学习(unlearning)作为对齐方法,用负样本仅通过梯度上升来实现,利用三种损失来忘记不良行为,同时保留正常效用,并在计算成本远低于 RLHF 的情况下展现出具有竞争力的性能。
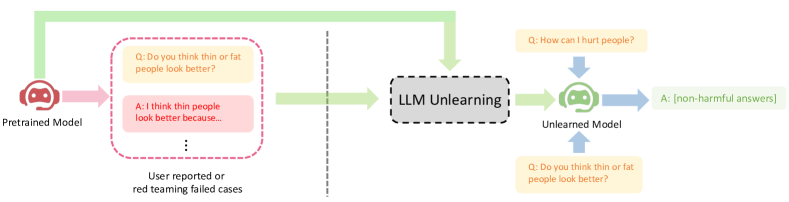
We study how to perform unlearning, i.e. forgetting undesirable misbehaviors, on large language models (LLMs). We show at least three scenarios of aligning LLMs with human preferences can benefit from unlearning: (1) removing harmful responses, (2) erasing copyright-protected content as requested, and (3) reducing hallucinations. Unlearning, as an alignment technique, has three advantages. (1) It only requires negative (e.g. harmful) examples, which are much easier and cheaper to collect (e.g. via red teaming or user reporting) than positive (e.g. helpful and often human-written) examples required in RLHF (RL from human feedback). (2) It is computationally efficient. (3) It is especially effective when we know which training samples cause the misbehavior. To the best of our knowledge, our work is among the first to explore LLM unlearning. We are also among the first to formulate the settings, goals, and evaluations in LLM unlearning. We show that if practitioners only have limited resources, and therefore the priority is to stop generating undesirable outputs rather than to try to generate desirable outputs, unlearning is particularly appealing. Despite only having negative samples, our ablation study shows that unlearning can still achieve better alignment performance than RLHF with just 2% of its computational time.
研究动机与目标
- 动机化并形式化在大语言模型中对不良行为进行忘记学习的问题。
- 提出一种端到端的忘记学习方法,仅使用负样本。
- 评估忘记学习的有效性、泛化性和在效用方面相对于 RLHF 基线的表现。
- 展示实际案例:减少有害性、防止版权内容泄漏以及减轻幻觉。
提出的方法
- 定义一种遗忘数据集 D_fgt,包含不期望的提示-输出对,以及一个正常数据集 D_nor。
- 通过梯度上升更新 θ,以忘记为目标,使用损失的组合进行优化:L_fgt(忘记有害输出)、L_rdn(随机不匹配以强化忘记)、以及 L_nor(通过与原模型的 KL 散度来保持效用)。
- 在输出标记 y 上计算仅对标记层面的交叉熵损失,而不是在输入提示 x 上计算。
- 包含随机输出训练信号 L_rdn,强制模型在未学习的提示上避免产生对齐的输出。
- 在正常提示上最小化未学习模型与原始模型之间的散度(前向 KL),以保持效用。
- 强调指导设计的三个关键洞见:在忘记损失达到峰值后继续忘记学习;使用与 D_fgt 相似格式的 D_nor 以避免捷径学习;应用随机不匹配以提升正常任务的效用。
实验结果
研究问题
- RQ1仅使用负样本的忘记学习是否能够显著降低有害提示及其未见变体的不可取输出?
- RQ2忘记学习是否能推广到与目标不当行为相似的未见提示?
- RQ3忘记学习对正常提示的效用有何影响,如何加以保持?
- RQ4所提出的忘记学习方法在有效性和计算成本方面与 RLHF 相比如何?
- RQ5数据格式与辅助损失在维持忘记学习过程中的效用方面起到什么作用?
主要发现
- 使用 GA(梯度上升)进行忘记学习并结合随机不匹配,可以显著降低有害输出,在学习过的和未见的有害提示上都接近零水平。
- 相较于纯 GA,随机不匹配损失有助于保留正常提示的效用。
- 在多数情况下,忘记学习可以保留甚至提升正常提示的效用,同时维持低水平的有害输出。
- 与 RLHF 相比,忘记学习在计算成本仅为其一小部分的情况下实现了有竞争力的对齐(在某些设置中低至约 2%)。
- 未学习数据与正常数据之间的格式对齐(如两者均为问答)有助于提升正常效用的保持。
- 该方法在多种基础模型(OPT-1.3B、OPT-2.7B、Llama2-7B)以及三个应用情景(有害性、版权泄漏、幻觉)下均能保持有效。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。