[论文解读] Large Language Models are Capable of Offering Cognitive Reappraisal, if Guided
在 RESORT 宪法的引导下,LLMs 可以为情感支持生成有针对性的认知重新评估,专家心理学家对比基线给出改进评分,开源模型接近 GPT-4 turbo 的性能;GPT-4 在评估重新评估时可以中等程度地同意专家评估。
Large language models (LLMs) have offered new opportunities for emotional support, and recent work has shown that they can produce empathic responses to people in distress. However, long-term mental well-being requires emotional self-regulation, where a one-time empathic response falls short. This work takes a first step by engaging with cognitive reappraisals, a strategy from psychology practitioners that uses language to targetedly change negative appraisals that an individual makes of the situation; such appraisals is known to sit at the root of human emotional experience. We hypothesize that psychologically grounded principles could enable such advanced psychology capabilities in LLMs, and design RESORT which consists of a series of reappraisal constitutions across multiple dimensions that can be used as LLM instructions. We conduct a first-of-its-kind expert evaluation (by clinical psychologists with M.S. or Ph.D. degrees) of an LLM's zero-shot ability to generate cognitive reappraisal responses to medium-length social media messages asking for support. This fine-grained evaluation showed that even LLMs at the 7B scale guided by RESORT are capable of generating empathic responses that can help users reappraise their situations.
研究动机与目标
- 推动以认知评估为基础的干预手段,用于长期情绪健康。
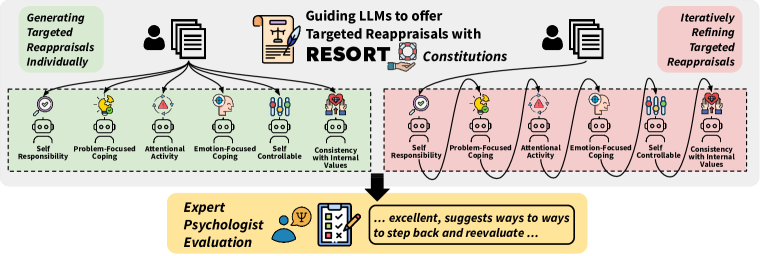
- 提出 RESORT,这是一个以心理学为依据、包含六个评估维度的框架,作为对 LLM 的指令。
- 评估在 RESORT 指导下,是否能让 LLM 在零样本条件下生成有针对性的重新评估,由专家心理学家评估。
- 比较开源 LLM 与 GPT-4 turbo 在生成重新评估方面的表现,并评估安全性、事实性与同理心。
提出的方法
- 介绍 RESORT,六个评估维度及其宪法指引重新评估的生成。
- 提出两种提示策略:个体化引导的重新评估和迭代式引导改进。
- 可选在生成重新评估之前加入明确的评估识别。
- 使用对齐、同理心、有害性和事实性等标准,由专家心理学家评估输出。
实验结果
研究问题
- RQ1在零样本设置中,LLMs 是否能生成与以心理学为基础的宪法(RESORT)对齐的有针对性的认知重新评估?
- RQ2显式的评估识别和/或迭代式改进是否提高重新评估的对齐度和同理心?
- RQ3开源 LLM 再加上 RESORT 在生成重新评估方面是否达到与 GPT-4 turbo 相近的性能?
- RQ4与人工撰写的参考相比,LLM 生成的重新评估在可靠性与安全性(有害性和事实性)方面如何?
主要发现
- 在 RESORT 指导下的 LLM 相对于基线显著提高了与宪法的一致性。
- 显式评估识别与迭代式改进进一步提高了对齐度和同理心分数。
- 开源模型(LLaMA-2 13B-chat,Mistral 7B-instruct)在重新评估任务上达到与 GPT-4 turbo 相近的性能。
- GPT-4 在评估重新评估时可以与专家评估者中等程度地达成一致,支持将其用作原型开发的自动评估工具。
- 研究中,大多数 LLM 生成的重新评估(约 98%)被评为不具伤害性,在很多情况下其事实性高于 Reddit 顶尖评论。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。