[论文解读] Large Language Models are Inconsistent and Biased Evaluators
本文表明 LLM 评估器在样本和提示之间存在偏见与不一致性,提出缓解方案,并在 RoSE 上展示了改进。
The zero-shot capability of Large Language Models (LLMs) has enabled highly flexible, reference-free metrics for various tasks, making LLM evaluators common tools in NLP. However, the robustness of these LLM evaluators remains relatively understudied; existing work mainly pursued optimal performance in terms of correlating LLM scores with human expert scores. In this paper, we conduct a series of analyses using the SummEval dataset and confirm that LLMs are biased evaluators as they: (1) exhibit familiarity bias-a preference for text with lower perplexity, (2) show skewed and biased distributions of ratings, and (3) experience anchoring effects for multi-attribute judgments. We also found that LLMs are inconsistent evaluators, showing low "inter-sample" agreement and sensitivity to prompt differences that are insignificant to human understanding of text quality. Furthermore, we share recipes for configuring LLM evaluators to mitigate these limitations. Experimental results on the RoSE dataset demonstrate improvements over the state-of-the-art LLM evaluators.
研究动机与目标
- 评估基于 LLM 的评估器在摘要任务中的偏见与一致性。
- 使用 SummEval 和 RoSE 数据集量化熟悉度偏见、评分偏见和锚定效应。
- 开发并验证缓解所识别问题的可实践方案。
- 在 RoSE CNNDM 与 SAMSum 分区上,将增强的 LLM 评估器与最先进基线进行比较。
提出的方法
- 使用多种提示和生成设置,在 SummEval 与 RoSE 上分析 LLM 评估器(GPT-3.5 与 GPT-4)。
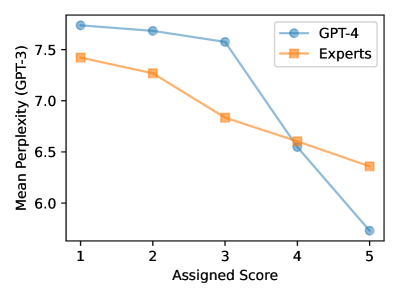
- 通过与评分的困惑度相关性来衡量熟悉度。
- 通过测试 1-5、1-10 和 1-100 等刻度,以及对多组样本取平均,来研究评分粒度。
- 通过在一次生成中预测多个属性以及重新排列属性来考察锚定效应。
- 使用 Krippendorff’s alpha 评估样本间一致性与标注者间一致性,并用 Kendall’s tau 与人类判断比较。
- 提出缓解策略的组合方案并在 RoSE 上验证,与 G-Eval 以及 Chiang & Lee (2023) 进行比较。
- 进行 RoSE CNNDM 与 SAMSum 分区的案例研究,以展示性能提升。
实验结果
研究问题
- RQ1LLM 评估器在摘要评估中是否表现出熟悉度偏见、评分偏见和锚定效应?
- RQ2相较于人类评分者,LLM 评估器在样本和提示变化之间的一致性如何?
- RQ3一整套具体的缓解方案是否能提升 LLM 评估器的可靠性与对齐度?
- RQ4与最先进的基线相比,所提出的方法在 RoSE 上是否产生统计显著的改进?
主要发现
- LLM 评估器表现出熟悉度偏见,相对于人类专家而言偏好低困惑度摘要。
- LLMs 显示评分偏见,偏好整十/整百的分数且粒度可变。
- 当一次输出中预测多个属性时出现锚定效应,进而 bias 后续分数。
- LLM 评估器的样本间一致性低于人类标注者的一致性,表明自我不一致。
- 移除源文档会显著降低评估器性能,表明过度依赖源特征。
- 一组组合方案,提供 1-10 评分与 0 temperature 非自释推理 prompts,在 RoSE CNNDM 与 SAMSum 分区上超越基线,达到 Kendall’s tau 约 0.22(同域)与 0.308(SAMSum)。
- RoSE 案例研究显示,所提方法在 CNNDM 与 SAMSum 上优于 G-Eval 与 Chiang & Lee (2023),具有统计显著性(自举法)。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。