[论文解读] Large Language Models as Optimizers
本文介绍 Optimization by PROMPTing (OPRO),使用 LLM 作为优化器在提示驱动循环中生成并评估新的解,并在 GSM8K 和 BBH 上展示了基于 LLM 的提示优化,表明由 LLM 优化的提示在某些任务中可超越人工设计的提示。
Optimization is ubiquitous. While derivative-based algorithms have been powerful tools for various problems, the absence of gradient imposes challenges on many real-world applications. In this work, we propose Optimization by PROmpting (OPRO), a simple and effective approach to leverage large language models (LLMs) as optimizers, where the optimization task is described in natural language. In each optimization step, the LLM generates new solutions from the prompt that contains previously generated solutions with their values, then the new solutions are evaluated and added to the prompt for the next optimization step. We first showcase OPRO on linear regression and traveling salesman problems, then move on to our main application in prompt optimization, where the goal is to find instructions that maximize the task accuracy. With a variety of LLMs, we demonstrate that the best prompts optimized by OPRO outperform human-designed prompts by up to 8% on GSM8K, and by up to 50% on Big-Bench Hard tasks. Code at https://github.com/google-deepmind/opro.
研究动机与目标
- 描述 LLM 如何通过基于过去解及其分数的迭代生成来充当优化器。
- 展示关于连续优化(线性回归)和离散优化(TSP)的案例研究,以说明能力与局限。
- 演示提示优化,其中 LLMs 优化提示以最大化 NLP 基准上的任务准确性。
- 评估多种 LLM 作为优化器和评分器,在 GSM8K 和 BBH 上以评估通用性与可迁移性。
提出的方法
- 定义 Optimization by PROMPTing (OPRO),其中给定元提示的 LLM 依据过去的解-分数历史生成新的候选解。
- 在每一步,评估新解并将其分数追加到元提示中的优化轨迹。
- 通过调整采样温度和每步生成多个候选解来纳入探索-开发的平衡。
- 使用含有优化问题描述、优化轨迹和示例问题的元提示来引导优化器。
- 将 OPRO 应用于数学任务(线性回归和 TSP)以展示黑盒优化能力。
- 将 OPRO 应用到提示优化:使用评分器 LLM 评估生成的提示,优化器 LLM 生成新提示,含有一个小的训练子集引导目标。
- 比较多种 LLMs 作为优化器(text-bison, PaLM 2-L, PaLM 2-L-IT, gpt-3.5-turbo, gpt-4)与评分器,在 GSM8K 与 BBH。
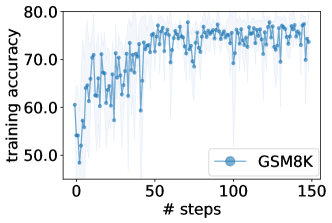
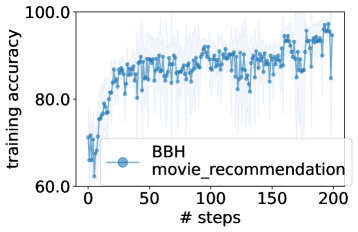
实验结果
研究问题
- RQ1LLMs 能否作为有效的优化器,利用纯提示交互同时解决连续与离散问题?
- RQ2LLMs 在像 GSM8K 和 BBH 这样的 NLP 基准上将提示优化到最大化任务准确性,效果如何?
- RQ3使用 LLMs 作为优化器时的局限性和稳定性考虑是什么,尤其是对较大规模的问题?
- RQ4不同优化器与评分器 LLM 组合对提示优化性能和可迁移性有何影响?
- RQ5优化后的提示在相关基准之间的迁移程度如何(例如 GSM8K 到 MultiArith 和 AQuA)?
主要发现
- OPRO 使 LLMs 能在各任务中生成新解并改进优化轨迹。
- 由 LLMs 优化的最佳提示在 GSM8K 上可超越零-shot 人工设计提示最多 8%,在 Big-Bench Hard 任务上可超越最多 50%。
- GPT-4、text-bison、PaLM 2-L-IT、PaLM 2-L 展现出不同的风格与优势,有些达到更快的收敛与更好的最优解。
- 在 TSP 的小规模问题中,GPT-4 明显优于其他 LLMs,但随着 n 增大,表现下降,在最优性差距方面传统启发式方法可能优于 LLMs。
- 提示优化表明较小的训练子集就足以引导优化,且优化后的提示可以迁移到相关的数学数据集。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。