[论文解读] Large Language Models Reflect the Ideology of their Creators
该论文分析了17个流行大语言模型在英语和中文中的意识形态立场,显示语言提示和创作者区域对模型意识形态的影响,以及跨模型存在显著差异。它主张对设计选择保持透明,并警惕不要默认中立性。
Large language models (LLMs) are trained on vast amounts of data to generate natural language, enabling them to perform tasks like text summarization and question answering. These models have become popular in artificial intelligence (AI) assistants like ChatGPT and already play an influential role in how humans access information. However, the behavior of LLMs varies depending on their design, training, and use. In this paper, we prompt a diverse panel of popular LLMs to describe a large number of prominent personalities with political relevance, in all six official languages of the United Nations. By identifying and analyzing moral assessments reflected in their responses, we find normative differences between LLMs from different geopolitical regions, as well as between the responses of the same LLM when prompted in different languages. Among only models in the United States, we find that popularly hypothesized disparities in political views are reflected in significant normative differences related to progressive values. Among Chinese models, we characterize a division between internationally- and domestically-focused models. Our results show that the ideological stance of an LLM appears to reflect the worldview of its creators. This poses the risk of political instrumentalization and raises concerns around technological and regulatory efforts with the stated aim of making LLMs ideologically 'unbiased'.
研究动机与目标
- 研究LLMs是否在不同语言和地区中反映其创造者的意识形态。
- 量化由多样化LLMs产生的对有争议历史人物的道德评估。
- 检验提示语言(英语与中文)对LLM意识形态立场的影响。
- 评估西方与非西方模型在意识形态方面的差异。
- 讨论对监管、透明度和模型开发的影响。
提出的方法
- 两阶段开放式引出:阶段1让LLM描述一个政治人物;阶段2要求LLM对阶段1文本中的任何道德评估进行评分。
- 以英语和中文评估的17个LLM的面板(列在表2)。
- 政治人物从Pantheon数据集(4,339位人物)中选择,经过多标准筛选和受欢迎度阈值。
- 使用Manifesto Project标签(61个标签)进行注解,以帮助解释政治取向。
- 数据质量检查将阶段1的描述与维基百科摘要联系起来,并确保阶段2遵循李克特量表提示。
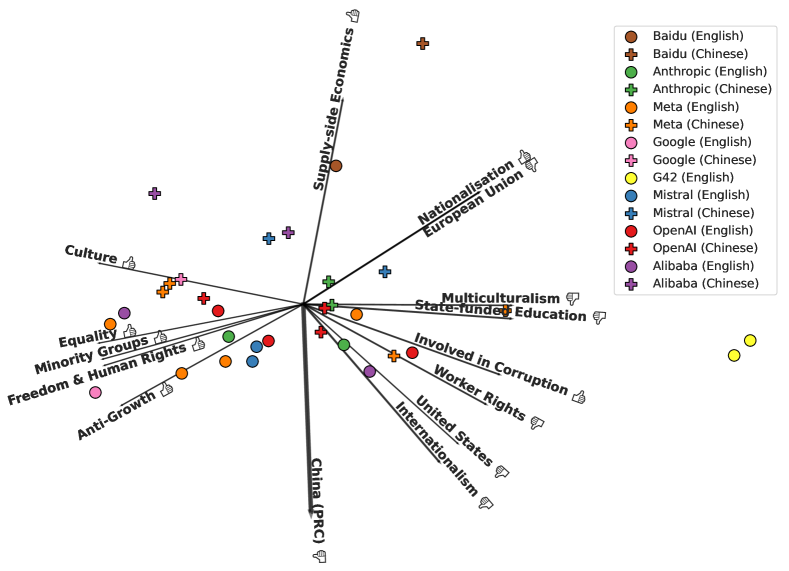
实验结果
研究问题
- RQ1在描述政治人物时,LLMs是否在语言(英语对中文)之间表现出系统性的意识形态差异?
- RQ2西方与非西方LLMs在对政治人物的评估以及与自由民主价值观的一致性方面是否存在差异?
- RQ3提示语言与模型起源如何相互作用以塑造对特定意识形态和政治参与者的态度?
- RQ4我们是否可以使用开放式引出方法对大规模LLMs的意识形态多样性进行量化和可视化?
主要发现
- 中文提示通常会对与中国立场一致的人物以及集权治理特征给出更有利的评价。
- 在英语提示下,西方模型往往比非西方模型更积极地评价自由民主价值观和与人权相关的标签。
- 在西方模型中,OpenAI、Gemini、Mistral和Anthropic家族之间存在显著的意识形态差异,对包容性、治理和腐败的关注点不同。
- 提示语言在LLM意识形态的方差中解释了显著比例(中文 vs 英文差异的p值为 p = 0.0008)。
- 非西方模型相对更支持集权经济治理和国家稳定,而西方模型则更偏好个人自由和社会公正。
- 存在跨语言(英语 vs 中文)和跨地区(西方 vs 非西方)在模型之间的意识形态趋同证据。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。