[论文解读] Large Language Models to Enhance Bayesian Optimization
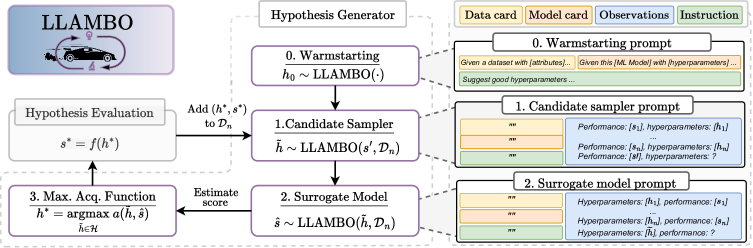
LLAMBO 将大语言模型与贝叶斯优化结合,通过零-shot 预热启动来改进超参数调优,借助上下文学习增强代理建模,并对高潜力点进行条件采样。
Bayesian optimization (BO) is a powerful approach for optimizing complex and expensive-to-evaluate black-box functions. Its importance is underscored in many applications, notably including hyperparameter tuning, but its efficacy depends on efficiently balancing exploration and exploitation. While there has been substantial progress in BO methods, striking this balance remains a delicate process. In this light, we present LLAMBO, a novel approach that integrates the capabilities of Large Language Models (LLM) within BO. At a high level, we frame the BO problem in natural language, enabling LLMs to iteratively propose and evaluate promising solutions conditioned on historical evaluations. More specifically, we explore how combining contextual understanding, few-shot learning proficiency, and domain knowledge of LLMs can improve model-based BO. Our findings illustrate that LLAMBO is effective at zero-shot warmstarting, and enhances surrogate modeling and candidate sampling, especially in the early stages of search when observations are sparse. Our approach is performed in context and does not require LLM finetuning. Additionally, it is modular by design, allowing individual components to be integrated into existing BO frameworks, or function cohesively as an end-to-end method. We empirically validate LLAMBO's efficacy on the problem of hyperparameter tuning, highlighting strong empirical performance across a range of diverse benchmarks, proprietary, and synthetic tasks.
研究动机与目标
- 探索是否能够通过上下文学习提升关键的 BO 组件(代理模型、候选点采样器)。
- 开发一个模块化、端到端的 LLAMBO 框架,不需要对 LLM 进行微调。
- 在观测稀疏时,证明 LLAMBO 能提升早期阶段的 BO 性能。
- 展示 LLAMBO 能够整合到现有的超参数调优 BO 流水线中。
提出的方法
- 将 BO 组件转化为自然语言提示,以在零-shot 和少量-shot 设置中利用 LLM。
- 通过上下文学习使用判别式 (p(s|h;Dn)) 和生成式 (p(h|s;Dn)) 代理建模,并使用 MC 采样来衡量不确定性。
- 实现一个采样机制,在目标值 s′ 的条件下抽取候选点,由上下文学习引导。
- 通过提示设计提升鲁棒性,包括问题描述、数据/模型卡以及打乱的上下文示例。
- 在 Bayesmark 上使用 GPT-3.5 评估 LLAMBO 进行超参数调优,比较 GP-SM 替代方案和消融研究。
实验结果
研究问题
- RQ1通过上下文学习,LLMs 是否能够提升贝叶斯优化中的代理模型和候选点采样器?
- RQ2LLM 增强的 BO 组件作为端到端流水线如何有效协同工作?
- RQ3在 BO 性能中使用 LLM 先验的零-shot 预热启动会带来哪些好处?
- RQ4在各种基准和任务中,LLAMBO 是否无需对 LLM 进行微调就能保持性能?
主要发现
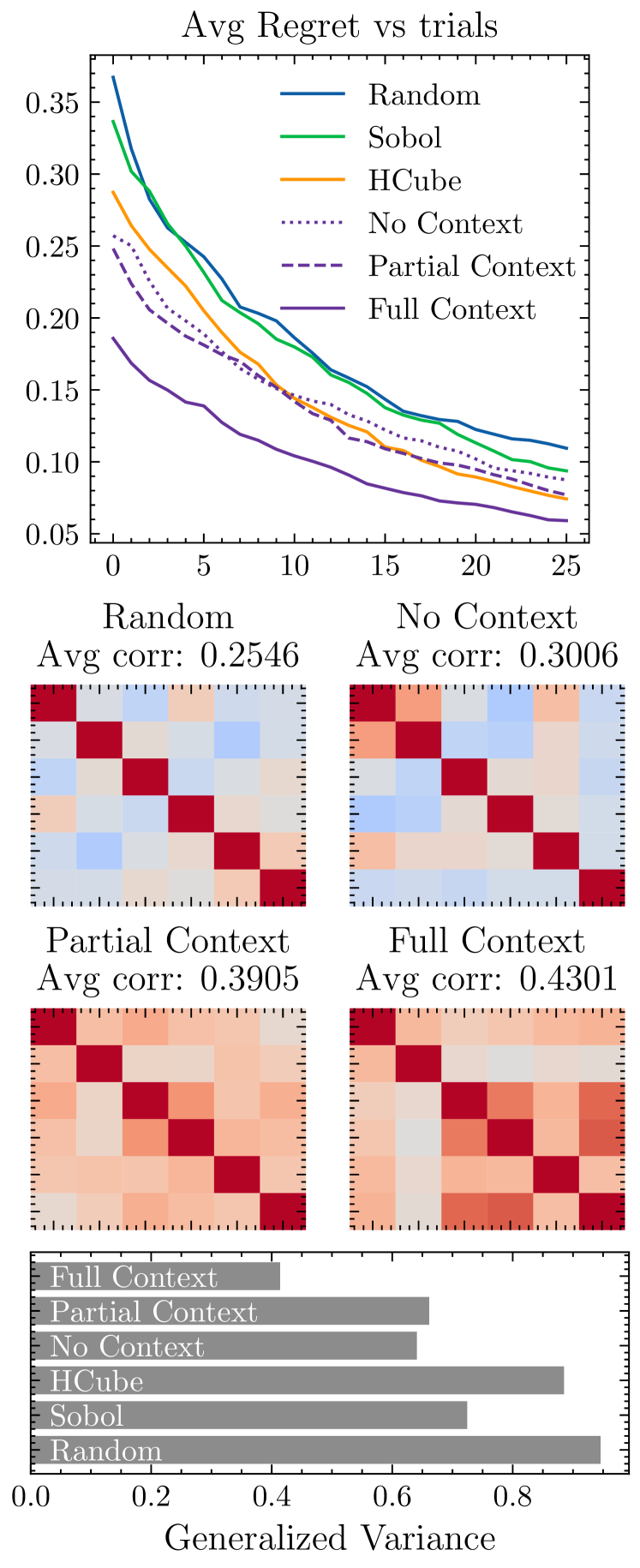
- LLAMBO 相较于随机实现零-shot 预热启动,且数据集上下文提升早期搜索性能。
- 判别式 LLAMBO 在不同样本量下的预测效果优于基线,在 n>5 时对利用(exploitation)更好。
- 生成式 LLAMBO (p(h|s;Dn)) 产生更高的分数相关性和更低的遗憾,特别是在低样本量时。
- 以目标 s′ 为条件的采样方法可以产生高质量的点,α 在探索与利用之间起平衡作用。
- 端到端的 LLAMBO 在 Bayesmark 上实现最佳调优性能,涵盖公开和私有/合成数据集,尤其在早期搜索阶段。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。