[论文解读] Leak Proof PDBBind: A Reorganized Dataset of Protein-Ligand Complexes for More Generalizable Binding Affinity Prediction
本文介绍 LP-PDBBind,一种对 PDBBind 的清理且防泄漏的重组,对其重新训练四个评分函数,并在如 BDB2020+ 这样的独立基准上展示了对基于三维结构的方法的泛化能力改善,同时强调对纯序列模型的收益有限。
Many physics-based and machine-learned scoring functions (SFs) used to predict protein-ligand binding free energies have been trained on the PDBBind dataset. However, it is controversial as to whether new SFs are actually improving since the general, refined, and core datasets of PDBBind are cross-contaminated with proteins and ligands with high similarity, and hence they may not perform comparably well in binding prediction of new protein-ligand complexes. In this work we have carefully prepared a cleaned PDBBind data set of non-covalent binders that are split into training, validation, and test datasets to control for data leakage, defined as proteins and ligands with high sequence and structural similarity. The resulting leak-proof (LP)-PDBBind data is used to retrain four popular SFs: AutoDock Vina, Random Forest (RF)-Score, InteractionGraphNet (IGN), and DeepDTA, to better test their capabilities when applied to new protein-ligand complexes. In particular we have formulated a new independent data set, BDB2020+, by matching high quality binding free energies from BindingDB with co-crystalized ligand-protein complexes from the PDB that have been deposited since 2020. Based on all the benchmark results, the retrained models using LP-PDBBind consistently perform better, with IGN especially being recommended for scoring and ranking applications for new protein-ligand systems.
研究动机与目标
- 通过创建一个清理、非共价的、且防泄漏的划分(LP-PDBBind),解决 PDBBind 数据集中的数据泄漏和质量不均问题。
- 评估在 LP-PDBBind 上重新训练现有评分函数对新蛋白-配体复合体泛化能力的影响。
- 提供一个独立基准(BDB2020+)来评估重新训练模型的迁移性能。
- 就哪些模型家族在无泄漏数据划分和基于 3D 结构表示方面受益最大提供指南。
提出的方法
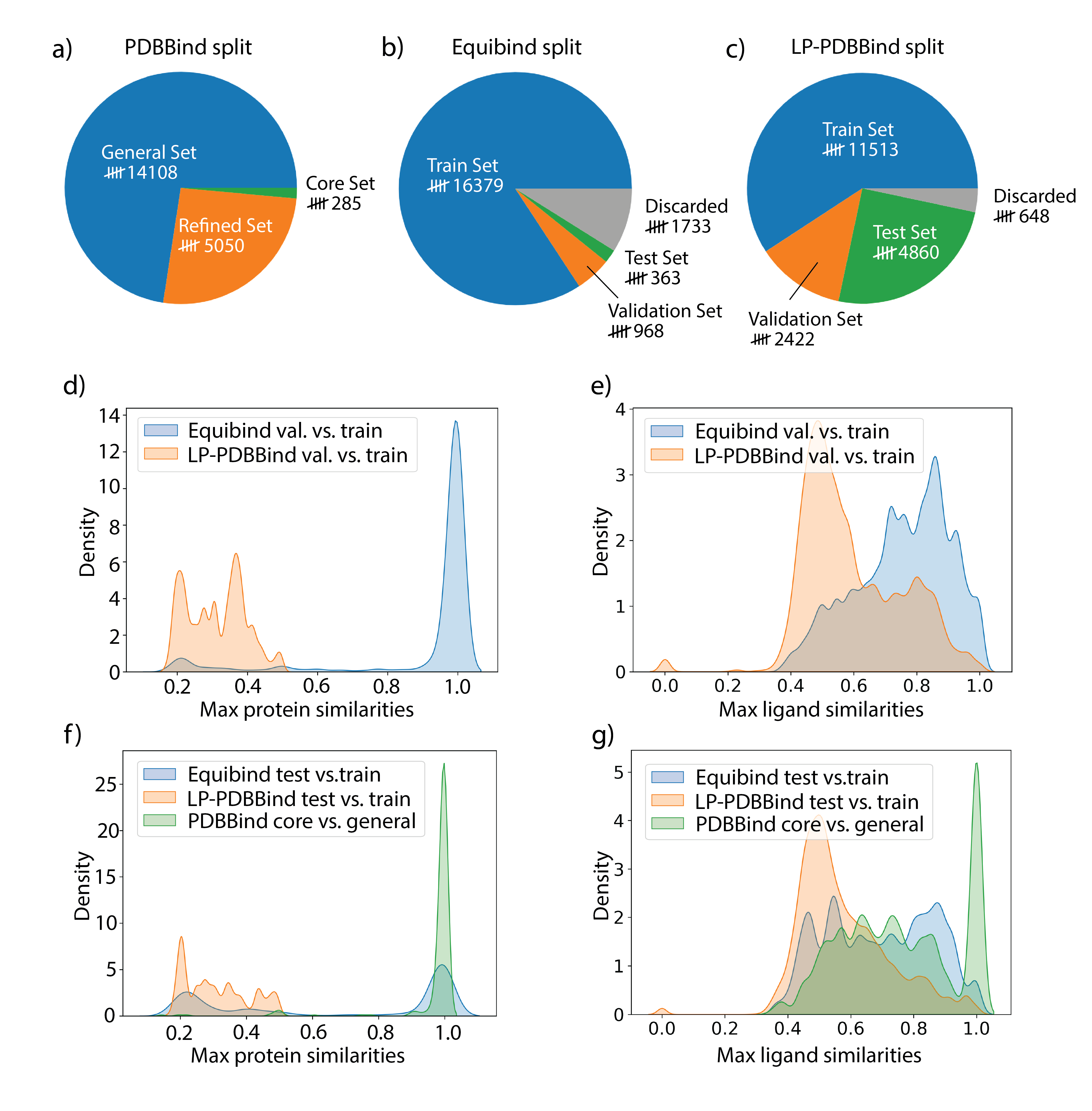
- 清理并筛选 PDBBind,生成一个非共价、高质量的子集(CL1,可选 CL2/CL3),并基于蛋白质类别定义一个基于相似性的泄漏控制划分。
- 通过 Morgan 指纹和 Dice 相似性计算配体相似性;在同一类别内通过序列比对计算蛋白质相似性;应用一个基于种子的迭代划分,以尽量减少训练集与测试集之间的泄漏。
- 在 LP-PDBBind 上重新训练四个评分函数家族:AutoDock Vina(重新加权的3D项)、RF-Score(基于原子类型接触的随机森林)、IGN(基于3D结构的图神经网络)和 DeepDTA(基于序列/SMILES 的基线)。
- 通过将最近的 BindingDB 记录与具有相似相似性控制的 PDB 结构匹配,构建 BDB2020+,作为用于评估的独立基准。
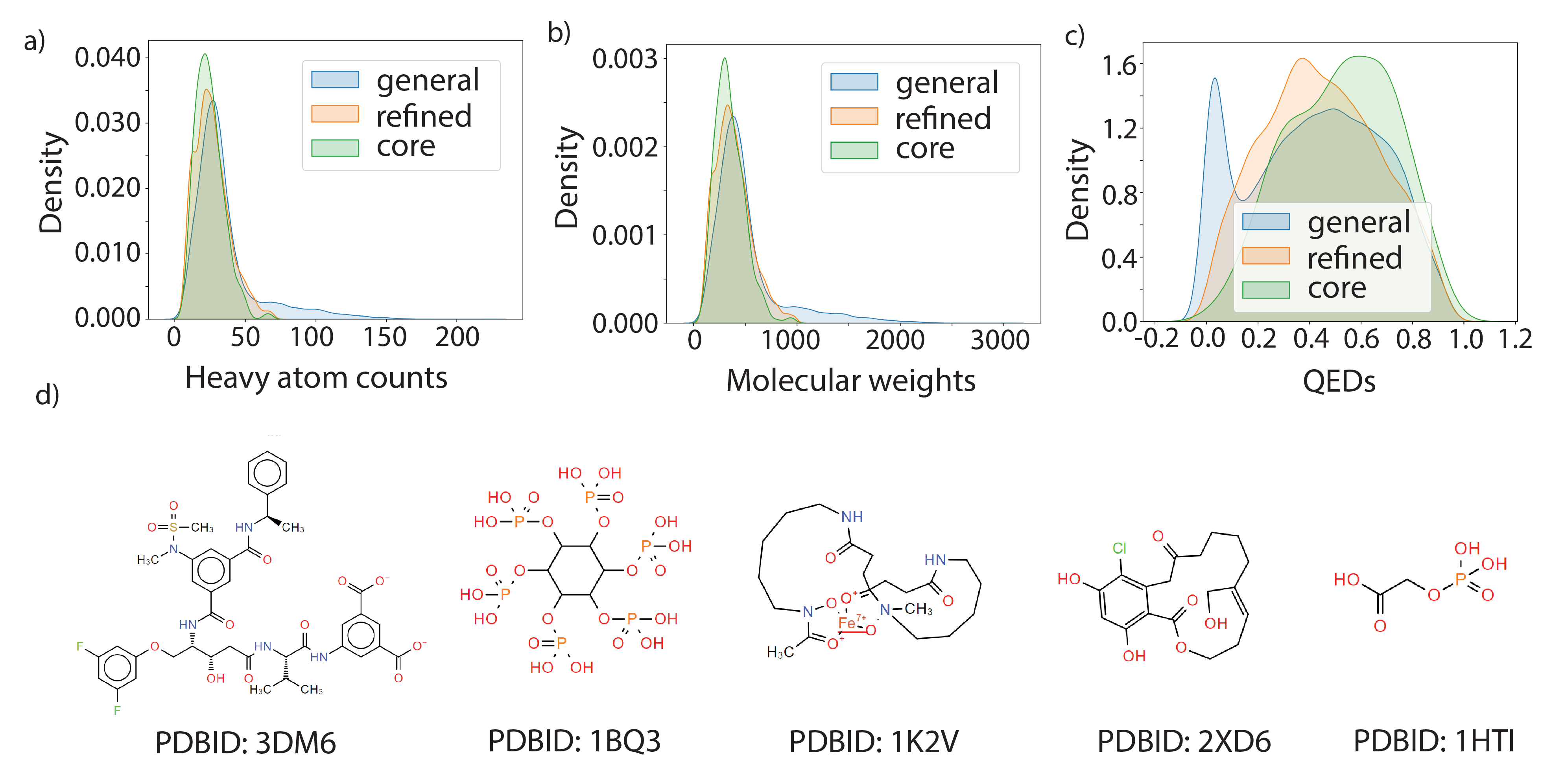
实验结果
研究问题
- RQ1通过 LP-PDBBind 移除数据泄漏是否能提升现有 SFs 对新型蛋白-配体复合体的泛化能力?
- RQ2在 LP-PDBBind 上训练并在独立基准上评估时,基于3D结构的模型与基于序列的模型相比如何?
- RQ3在 LP-PDBBind 上重新训练对训练、验证和测试集,以及像 BDB2020+ 这样的独立基准的性能指标有何影响?
- RQ4在无泄漏重训练后,哪些模型家族对新颖复合体和独立数据集表现出最强的可迁移性?
主要发现
- 在 LP-PDBBind 上重新训练提高了基于3D结构的模型(IGN、AutoDock Vina、RF-Score)在独立基准如 BDB2020+ 上的表现,表明更好的泛化能力。
- 重新训练后,IGN 在对新蛋白-配体系统的打分和排序方面始终处于最佳之列。
- DeepDTA(1D 序列为基础)重新训练后泛化能力下降,在独立基准上的表现亦不如基于3D的模型。
- 原始 MLSF 模型在易泄漏的核心上因训练数据重叠而表现夸大;LP-PDBBind 揭示了它们真正的泛化差距。
- LP-PDBBind 划分得到一个更大且与训练数据相似性受控的测试集,为迁移能力提供更现实的评估。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。