[论文解读] Learning Interactive Real-World Simulators
本文提出 UniSim,一种通用的动作条件视频扩散模型,结合多样化的互联网数据集来模拟现实世界互动,并训练可转移到现实世界的视觉-语言与强化学习策略,无需额外的真实数据训练。
Generative models trained on internet data have revolutionized how text, image, and video content can be created. Perhaps the next milestone for generative models is to simulate realistic experience in response to actions taken by humans, robots, and other interactive agents. Applications of a real-world simulator range from controllable content creation in games and movies, to training embodied agents purely in simulation that can be directly deployed in the real world. We explore the possibility of learning a universal simulator (UniSim) of real-world interaction through generative modeling. We first make the important observation that natural datasets available for learning a real-world simulator are often rich along different dimensions (e.g., abundant objects in image data, densely sampled actions in robotics data, and diverse movements in navigation data). With careful orchestration of diverse datasets, each providing a different aspect of the overall experience, we can simulate the visual outcome of both high-level instructions such as "open the drawer" and low-level controls from otherwise static scenes and objects. We use the simulator to train both high-level vision-language policies and low-level reinforcement learning policies, each of which can be deployed in the real world in zero shot after training purely in simulation. We also show that other types of intelligence such as video captioning models can benefit from training with simulated experience, opening up even wider applications. Video demos can be found at https://universal-simulator.github.io.
研究动机与目标
- 说明需要一个能够融合多样数据源的通用、动作条件的现实世界模拟器。
- 提出一个统一的“动作在视频输入输出”框架,用于学习预测性的观测模型。
- 展示长时程、多模态模拟如何训练可转移到现实机器人之上的高级和低级策略。
- 展示额外应用,如使用仿真数据训练视频字幕/描述和广义视觉-语言模型等。
提出的方法
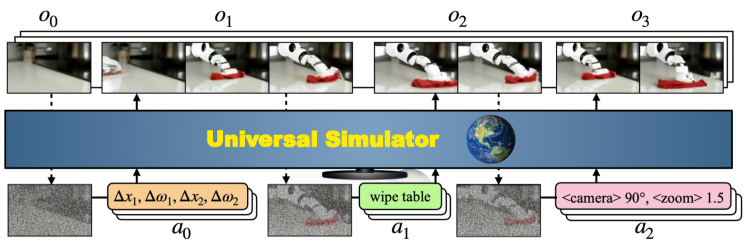
- 通过将文本、语言描述和运动控制转换为连续嵌入来形成统一的动作空间。
- 用带去噪网络 epsilon_theta 的视频扩散模型将 UniSim 训练为观测预测模型 p(o_t|h_{t-1},a_{t-1})。
- 用最近的历史帧对扩散模型进行条件化,以实现自回归的长时程视频生成。
- 使用无分类器引导将动作条件融入扩散过程。
- 将条件帧复制到未来步骤,并应用带有交错的时序与空间注意力的视频 U-Net 架构。
- 在真实机器人、人类活动、全景和互联网图像文本数据集等组合上进行训练,利用领域标识符来帮助低数据域。

实验结果
研究问题
- RQ1一个单一的、动作条件的视频扩散模型是否能够融合多样数据集来模拟真实世界的互动?
- RQ2长时程模拟是否能够有效训练可转移到现实任务的高级视觉-语言策略和低级强化学习控制器?
- RQ3仿真数据是否能够提升非具身任务,如视频字幕/描述和广义视觉-语言模型?
- RQ4当前通用模拟器在记忆、动作真实感和域外泛化方面有哪些局限?
主要发现
- UniSim 能在操作和导航任务中执行丰富动作和长时程仿真。
- 基于自回归扩散的观测预测产生以动作为条件的时间上连贯的视频序列。
- 完全在仿真中训练的视觉-语言策略和强化学习控制器可以在零样部署中转移到真实机器人。
- 仿真数据可以提升视频字幕模型,以及对长时程任务的仿真事后数据的价值。
- 对历史帧进行条件化可以提升生成质量;历史过远可能降低性能。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。